 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdvancing Continual Learning for Robust Deepfake Audio Classification
Jul 14, 2024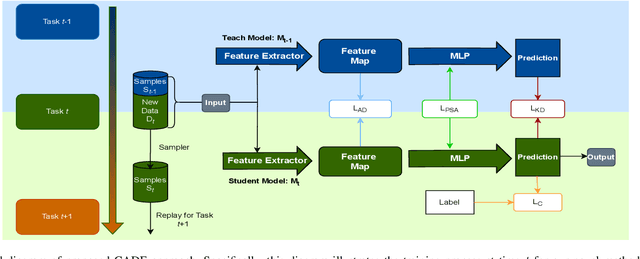



The emergence of new spoofing attacks poses an increasing challenge to audio security. Current detection methods often falter when faced with unseen spoofing attacks. Traditional strategies, such as retraining with new data, are not always feasible due to extensive storage. This paper introduces a novel continual learning method Continual Audio Defense Enhancer (CADE). First, by utilizing a fixed memory size to store randomly selected samples from previous datasets, our approach conserves resources and adheres to privacy constraints. Additionally, we also apply two distillation losses in CADE. By distillation in classifiers, CADE ensures that the student model closely resembles that of the teacher model. This resemblance helps the model retain old information while facing unseen data. We further refine our model's performance with a novel embedding similarity loss that extends across multiple depth layers, facilitating superior positive sample alignment. Experiments conducted on the ASVspoof2019 dataset show that our proposed method outperforms the baseline methods.