 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContext-aware LLM-based AI Agents for Human-centered Energy Management Systems in Smart Buildings
Dec 31, 2025This study presents a conceptual framework and a prototype assessment for Large Language Model (LLM)-based Building Energy Management System (BEMS) AI agents to facilitate context-aware energy management in smart buildings through natural language interaction. The proposed framework comprises three modules: perception (sensing), central control (brain), and action (actuation and user interaction), forming a closed feedback loop that captures, analyzes, and interprets energy data to respond intelligently to user queries and manage connected appliances. By leveraging the autonomous data analytics capabilities of LLMs, the BEMS AI agent seeks to offer context-aware insights into energy consumption, cost prediction, and device scheduling, thereby addressing limitations in existing energy management systems. The prototype's performance was evaluated using 120 user queries across four distinct real-world residential energy datasets and different evaluation metrics, including latency, functionality, capability, accuracy, and cost-effectiveness. The generalizability of the framework was demonstrated using ANOVA tests. The results revealed promising performance, measured by response accuracy in device control (86%), memory-related tasks (97%), scheduling and automation (74%), and energy analysis (77%), while more complex cost estimation tasks highlighted areas for improvement with an accuracy of 49%. This benchmarking study moves toward formalizing the assessment of LLM-based BEMS AI agents and identifying future research directions, emphasizing the trade-off between response accuracy and computational efficiency.
DEGAN: Time Series Anomaly Detection using Generative Adversarial Network Discriminators and Density Estimation
Oct 05, 2022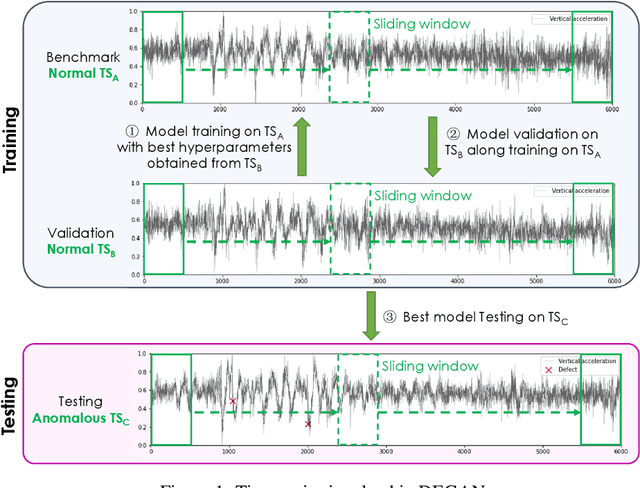

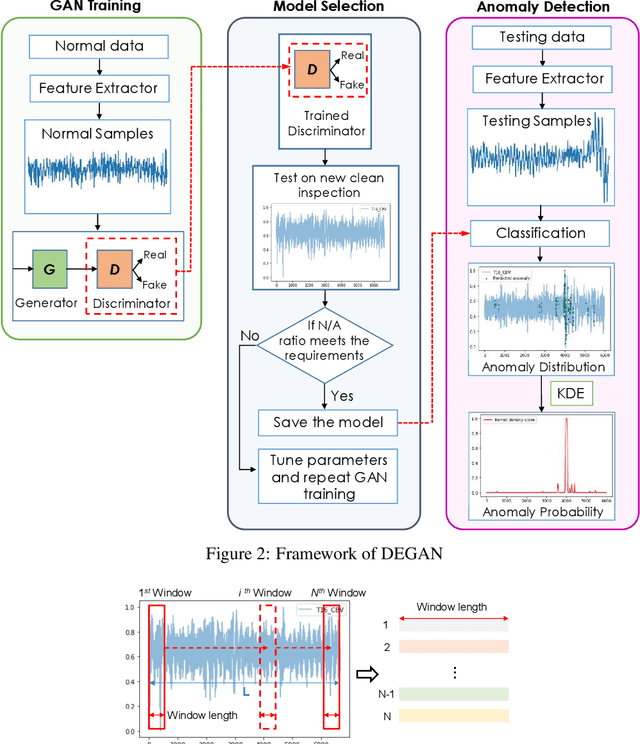

Developing efficient time series anomaly detection techniques is important to maintain service quality and provide early alarms. Generative neural network methods are one class of the unsupervised approaches that are achieving increasing attention in recent years. In this paper, we have proposed an unsupervised Generative Adversarial Network (GAN)-based anomaly detection framework, DEGAN. It relies solely on normal time series data as input to train a well-configured discriminator (D) into a standalone anomaly predictor. In this framework, time series data is processed by the sliding window method. Expected normal patterns in data are leveraged to develop a generator (G) capable of generating normal data patterns. Normal data is also utilized in hyperparameter tuning and D model selection steps. Validated D models are then extracted and applied to evaluate unseen (testing) time series and identify patterns that have anomalous characteristics. Kernel density estimation (KDE) is applied to data points that are likely to be anomalous to generate probability density functions on the testing time series. The segments with the highest relative probabilities are detected as anomalies. To evaluate the performance, we tested on univariate acceleration time series for five miles of a Class I railroad track. We implemented the framework to detect the real anomalous observations identified by operators. The results show that leveraging the framework with a CNN D architecture results in average best recall and precision of 80% and 86%, respectively, which demonstrates that a well-trained standalone D model has the potential to be a reliable anomaly detector. Moreover, the influence of GAN hyperparameters, GAN architectures, sliding window sizes, clustering of time series, and model validation with labeled/unlabeled data were also investigated.
Using Statistical Models to Detect Occupancy in Buildings through Monitoring VOC, CO$_2$, and other Environmental Factors
Mar 07, 2022
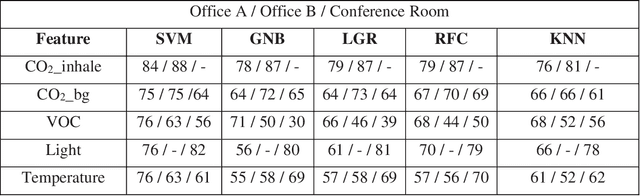
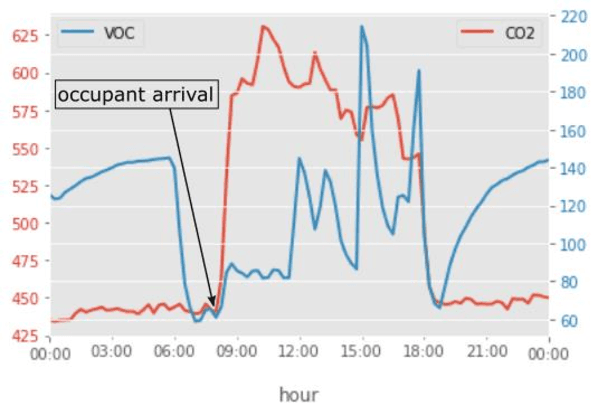
Dynamic models of occupancy patterns have shown to be effective in optimizing building-systems operations. Previous research has relied on CO$_2$ sensors and vision-based techniques to determine occupancy patterns. Vision-based techniques provide highly accurate information; however, they are very intrusive. Therefore, motion or CO$_2$ sensors are more widely adopted worldwide. Volatile Organic Compounds (VOCs) are another pollutant originating from the occupants. However, a limited number of studies have evaluated the impact of occupants on the VOC level. In this paper, continuous measurements of CO$_2$, VOC, light, temperature, and humidity were recorded in a 17,000 sqft open office space for around four months. Using different statistical models (e.g., SVM, K-Nearest Neighbors, and Random Forest) we evaluated which combination of environmental factors provides more accurate insights on occupant presence. Our preliminary results indicate that VOC is a good indicator of occupancy detection in some cases. It is also concluded that proper feature selection and developing appropriate global occupancy detection models can reduce the cost and energy of data collection without a significant impact on accuracy.
Two-stage building energy consumption clustering based on temporal and peak demand patterns
Aug 29, 2020



Analyzing smart meter data to understand energy consumption patterns helps utilities and energy providers perform customized demand response operations. Existing energy consumption segmentation techniques use assumptions that could result in reduced quality of clusters in representing their members. We address this limitation by introducing a two-stage clustering method that more accurately captures load shape temporal patterns and peak demands. In the first stage, load shapes are clustered by allowing a large number of clusters to accurately capture variations in energy use patterns and cluster centroids are extracted by accounting for shape misalignments. In the second stage, clusters of similar centroid and power magnitude range are merged by using Dynamic Time Warping. We used three datasets consisting of ~250 households (~15000 profiles) to demonstrate the performance improvement, compared to baseline methods, and discuss the impact on energy management.
An Automated Spectral Clustering for Multi-scale Data
Feb 06, 2019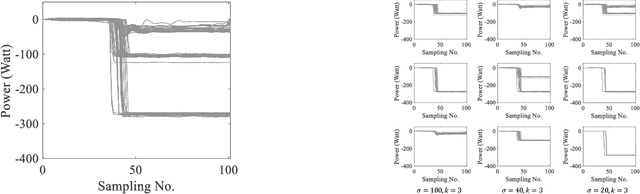
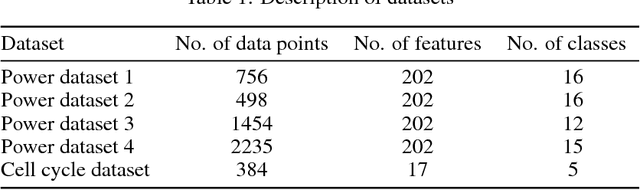
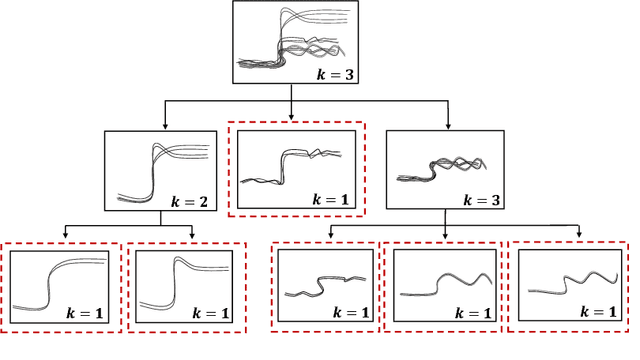
Spectral clustering algorithms typically require a priori selection of input parameters such as the number of clusters, a scaling parameter for the affinity measure, or ranges of these values for parameter tuning. Despite efforts for automating the process of spectral clustering, the task of grouping data in multi-scale and higher dimensional spaces is yet to be explored. This study presents a spectral clustering heuristic algorithm that obviates the need for an input by estimating the parameters from the data itself. Specifically, it introduces the heuristic of iterative eigengap search with (1) global scaling and (2) local scaling. These approaches estimate the scaling parameter and implement iterative eigengap quantification along a search tree to reveal dissimilarities at different scales of a feature space and identify clusters. The performance of these approaches has been tested on various real-world datasets of power variation with multi-scale nature and gene expression. Our findings show that iterative eigengap search with a PCA-based global scaling scheme can discover different patterns with an accuracy of higher than 90% in most cases without asking for a priori input information.