 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemLink: A Semantic-Aware Automated Test Oracle for Hyperlink Verification using Siamese Sentence-BERT
Apr 07, 2026Web applications rely heavily on hyperlinks to connect disparate information resources. However, the dynamic nature of the web leads to link rot, where targets become unavailable, and more insidiously, semantic drift, where a valid HTTP 200 connection exists, but the target content no longer aligns with the source context. Traditional verification tools, which primarily function as crash oracles by checking HTTP status codes, often fail to detect semantic inconsistencies, thereby compromising web integrity and user experience. While Large Language Models (LLMs) offer semantic understanding, they suffer from high latency, privacy concerns, and prohibitive costs for large-scale regression testing. In this paper, we propose SemLink, a novel automated test oracle for semantic hyperlink verification. SemLink leverages a Siamese Neural Network architecture powered by a pre-trained Sentence-BERT (SBERT) backbone to compute the semantic coherence between a hyperlink's source context (anchor text, surrounding DOM elements, and visual features) and its target page content. To train and evaluate our model, we introduce the Hyperlink-Webpage Positive Pairs (HWPPs) dataset, a rigorously constructed corpus of over 60,000 semantic pairs. Our evaluation demonstrates that SemLink achieves a Recall of 96.00%, comparable to state-of-the-art LLMs (GPT-5.2), while operating approximately 47.5 times faster and requiring significantly fewer computational resources. This work bridges the gap between traditional syntactic checkers and expensive generative AI, offering a robust and efficient solution for automated web quality assurance.
GNN-enhanced Traffic Anomaly Detection for Next-Generation SDN-Enabled Consumer Electronics
Oct 08, 2025

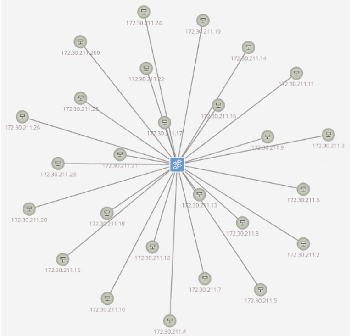

Consumer electronics (CE) connected to the Internet of Things are susceptible to various attacks, including DDoS and web-based threats, which can compromise their functionality and facilitate remote hijacking. These vulnerabilities allow attackers to exploit CE for broader system attacks while enabling the propagation of malicious code across the CE network, resulting in device failures. Existing deep learning-based traffic anomaly detection systems exhibit high accuracy in traditional network environments but are often overly complex and reliant on static infrastructure, necessitating manual configuration and management. To address these limitations, we propose a scalable network model that integrates Software-defined Networking (SDN) and Compute First Networking (CFN) for next-generation CE networks. In this network model, we propose a Graph Neural Networks-based Network Anomaly Detection framework (GNN-NAD) that integrates SDN-based CE networks and enables the CFN architecture. GNN-NAD uniquely fuses a static, vulnerability-aware attack graph with dynamic traffic features, providing a holistic view of network security. The core of the framework is a GNN model (GSAGE) for graph representation learning, followed by a Random Forest (RF) classifier. This design (GSAGE+RF) demonstrates superior performance compared to existing feature selection methods. Experimental evaluations on CE environment reveal that GNN-NAD achieves superior metrics in accuracy, recall, precision, and F1 score, even with small sample sizes, exceeding the performance of current network anomaly detection methods. This work advances the security and efficiency of next-generation intelligent CE networks.
Automated Vulnerability Detection Using Deep Learning Technique
Oct 29, 2024
Our work explores the utilization of deep learning, specifically leveraging the CodeBERT model, to enhance code security testing for Python applications by detecting SQL injection vulnerabilities. Unlike traditional security testing methods that may be slow and error-prone, our approach transforms source code into vector representations and trains a Long Short-Term Memory (LSTM) model to identify vulnerable patterns. When compared with existing static application security testing (SAST) tools, our model displays superior performance, achieving higher precision, recall, and F1-score. The study demonstrates that deep learning techniques, particularly with CodeBERT's advanced contextual understanding, can significantly improve vulnerability detection, presenting a scalable methodology applicable to various programming languages and vulnerability types.
Using Semantic Similarity for Input Topic Identification in Crawling-based Web Application Testing
Aug 23, 2016

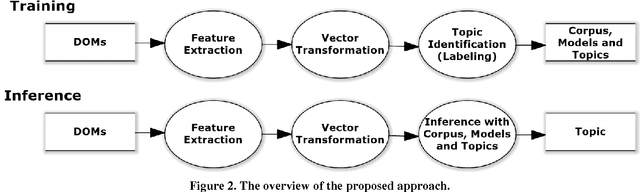

To automatically test web applications, crawling-based techniques are usually adopted to mine the behavior models, explore the state spaces or detect the violated invariants of the applications. However, in existing crawlers, rules for identifying the topics of input text fields, such as login ids, passwords, emails, dates and phone numbers, have to be manually configured. Moreover, the rules for one application are very often not suitable for another. In addition, when several rules conflict and match an input text field to more than one topics, it can be difficult to determine which rule suggests a better match. This paper presents a natural-language approach to automatically identify the topics of encountered input fields during crawling by semantically comparing their similarities with the input fields in labeled corpus. In our evaluation with 100 real-world forms, the proposed approach demonstrated comparable performance to the rule-based one. Our experiments also show that the accuracy of the rule-based approach can be improved by up to 19% when integrated with our approach.
PAC Learning-Based Verification and Model Synthesis
Nov 03, 2015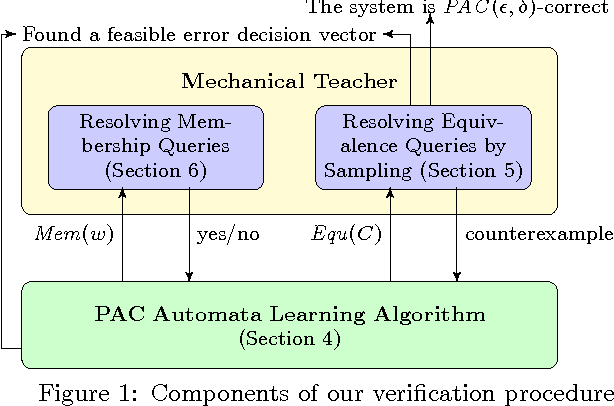
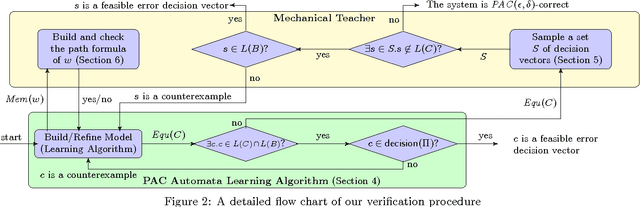
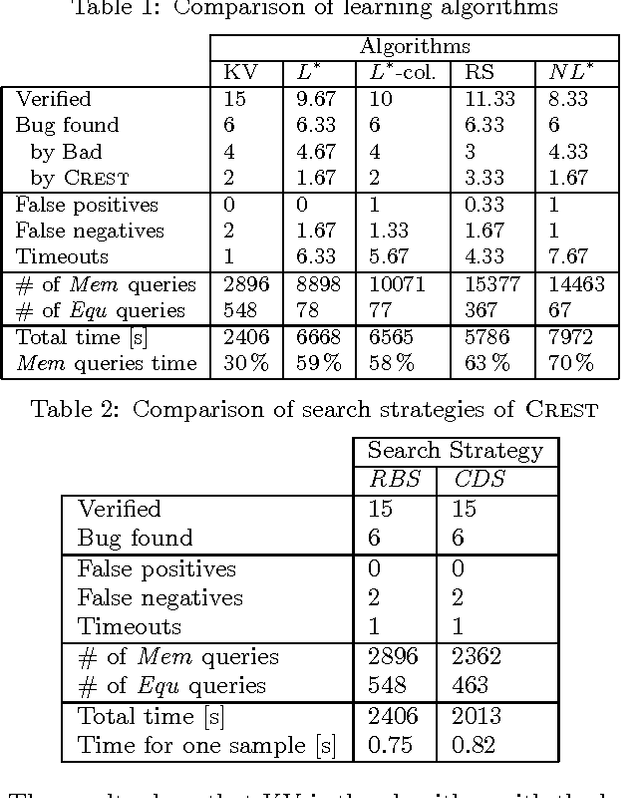
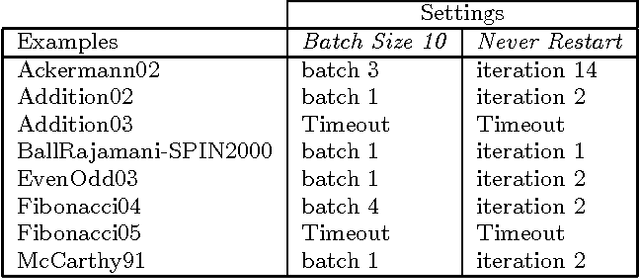
We introduce a novel technique for verification and model synthesis of sequential programs. Our technique is based on learning a regular model of the set of feasible paths in a program, and testing whether this model contains an incorrect behavior. Exact learning algorithms require checking equivalence between the model and the program, which is a difficult problem, in general undecidable. Our learning procedure is therefore based on the framework of probably approximately correct (PAC) learning, which uses sampling instead and provides correctness guarantees expressed using the terms error probability and confidence. Besides the verification result, our procedure also outputs the model with the said correctness guarantees. Obtained preliminary experiments show encouraging results, in some cases even outperforming mature software verifiers.