 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUsing Semantic Similarity for Input Topic Identification in Crawling-based Web Application Testing
Aug 23, 2016

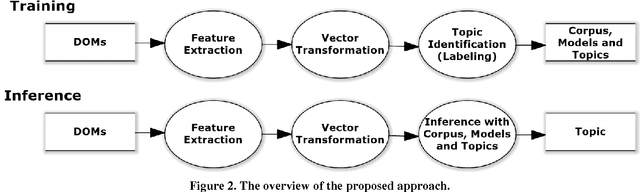

To automatically test web applications, crawling-based techniques are usually adopted to mine the behavior models, explore the state spaces or detect the violated invariants of the applications. However, in existing crawlers, rules for identifying the topics of input text fields, such as login ids, passwords, emails, dates and phone numbers, have to be manually configured. Moreover, the rules for one application are very often not suitable for another. In addition, when several rules conflict and match an input text field to more than one topics, it can be difficult to determine which rule suggests a better match. This paper presents a natural-language approach to automatically identify the topics of encountered input fields during crawling by semantically comparing their similarities with the input fields in labeled corpus. In our evaluation with 100 real-world forms, the proposed approach demonstrated comparable performance to the rule-based one. Our experiments also show that the accuracy of the rule-based approach can be improved by up to 19% when integrated with our approach.