 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredicting Heart Failure with Attention Learning Techniques Utilizing Cardiovascular Data
Jul 11, 2024
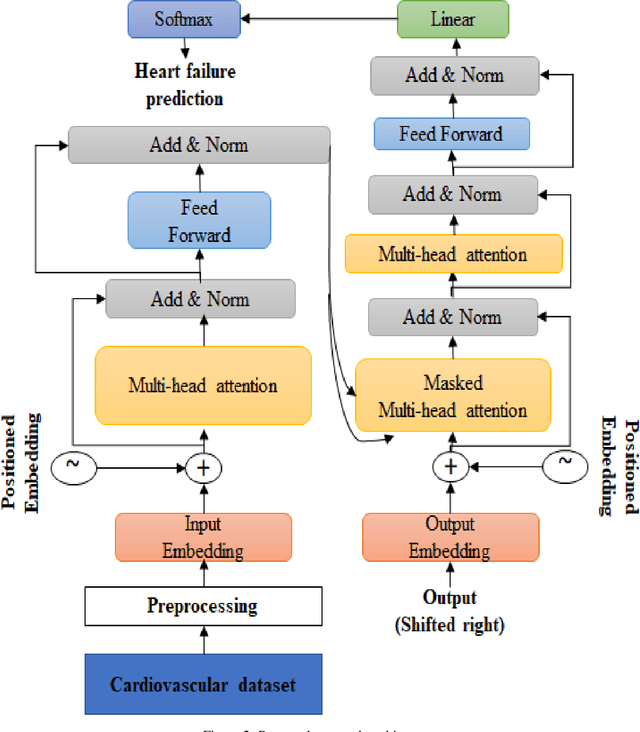
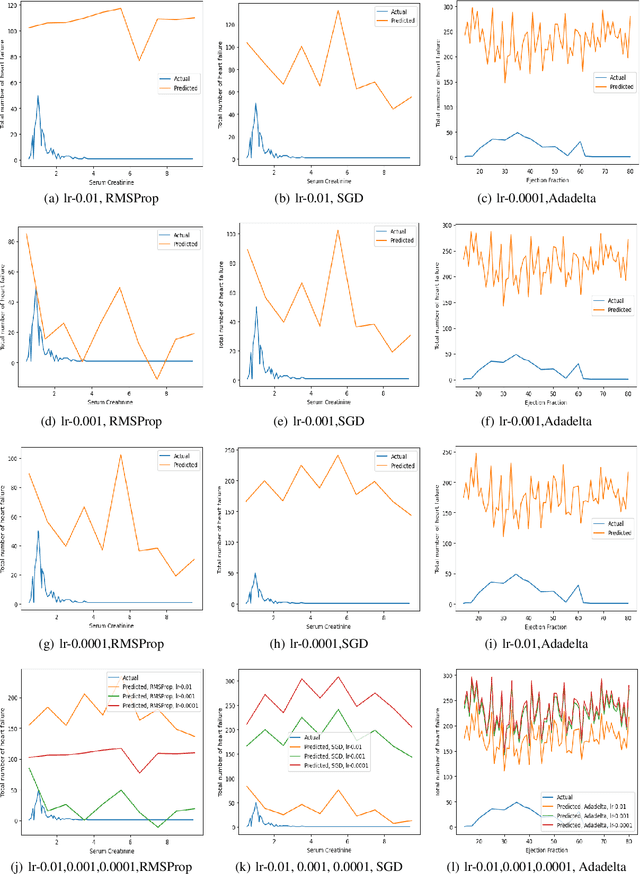
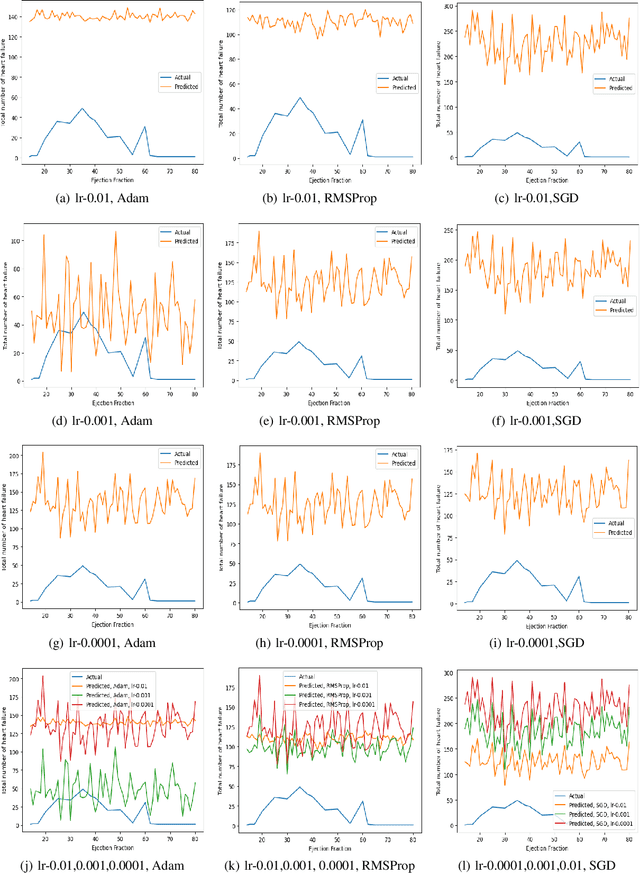
Cardiovascular diseases (CVDs) encompass a group of disorders affecting the heart and blood vessels, including conditions such as coronary artery disease, heart failure, stroke, and hypertension. In cardiovascular diseases, heart failure is one of the main causes of death and also long-term suffering in patients worldwide. Prediction is one of the risk factors that is highly valuable for treatment and intervention to minimize heart failure. In this work, an attention learning-based heart failure prediction approach is proposed on EHR(electronic health record) cardiovascular data such as ejection fraction and serum creatinine. Moreover, different optimizers with various learning rate approaches are applied to fine-tune the proposed approach. Serum creatinine and ejection fraction are the two most important features to predict the patient's heart failure. The computational result shows that the RMSProp optimizer with 0.001 learning rate has a better prediction based on serum creatinine. On the other hand, the combination of SGD optimizer with 0.01 learning rate exhibits optimum performance based on ejection fraction features. Overall, the proposed attention learning-based approach performs very efficiently in predicting heart failure compared to the existing state-of-the-art such as LSTM approach.
Efficient dynamic point cloud coding using Slice-Wise Segmentation
Aug 17, 2022



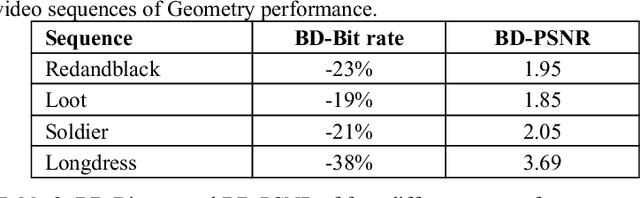
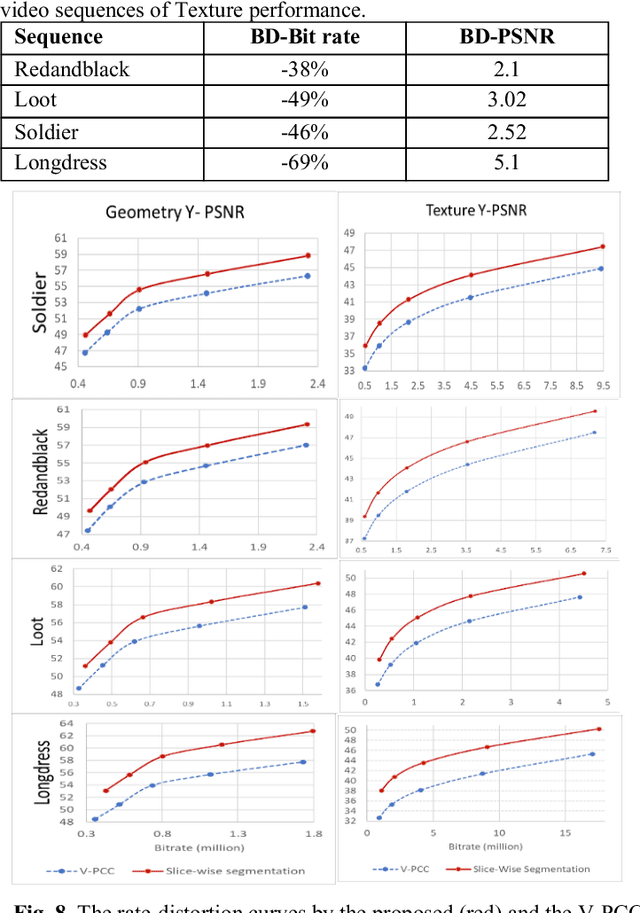
With the fast growth of immersive video sequences, achieving seamless and high-quality compressed 3D content is even more critical. MPEG recently developed a video-based point cloud compression (V-PCC) standard for dynamic point cloud coding. However, reconstructed point clouds using V-PCC suffer from different artifacts, including losing data during pre-processing before applying existing video coding techniques, e.g., High-Efficiency Video Coding (HEVC). Patch generations and self-occluded points in the 3D to the 2D projection are the main reasons for missing data using V-PCC. This paper proposes a new method that introduces overlapping slicing as an alternative to patch generation to decrease the number of patches generated and the amount of data lost. In the proposed method, the entire point cloud has been cross-sectioned into variable-sized slices based on the number of self-occluded points so that data loss can be minimized in the patch generation process and projection. For this, a variable number of layers are considered, partially overlapped to retain the self-occluded points. The proposed method's added advantage is to reduce the bits requirement and to encode geometric data using the slicing base position. The experimental results show that the proposed method is much more flexible than the standard V-PCC method, improves the rate-distortion performance, and decreases the data loss significantly compared to the standard V-PCC method.
Dynamic Point Cloud Compression with Cross-Sectional Approach
Apr 25, 2022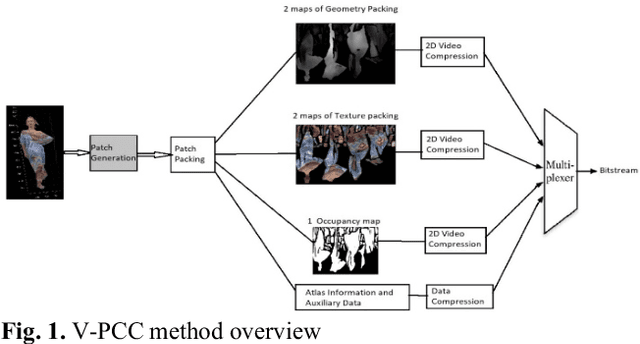

The recent development of dynamic point clouds has introduced the possibility of mimicking natural reality, and greatly assisting quality of life. However, to broadcast successfully, the dynamic point clouds require higher compression due to their huge volume of data compared to the traditional video. Recently, MPEG finalized a Video-based Point Cloud Compression standard known as V-PCC. However, V-PCC requires huge computational time due to expensive normal calculation and segmentation, sacrifices some points to limit the number of 2D patches, and cannot occupy all spaces in the 2D frame. The proposed method addresses these limitations by using a novel cross-sectional approach. This approach reduces expensive normal estimation and segmentation, retains more points, and utilizes more spaces for 2D frame generation compared to the VPCC. The experimental results using standard video sequences show that the proposed technique can achieve better compression in both geometric and texture data compared to the V-PCC standard.