 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Point Cloud Compression with Cross-Sectional Approach
Paper and Code
Apr 25, 2022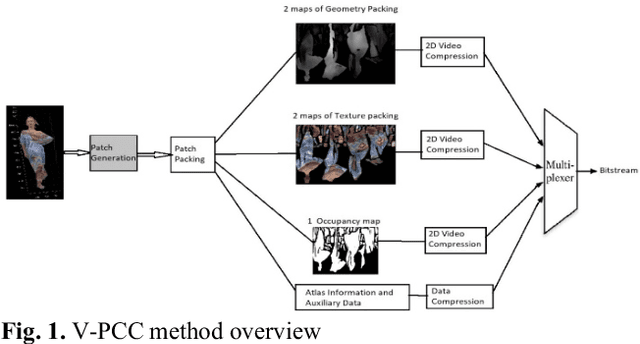
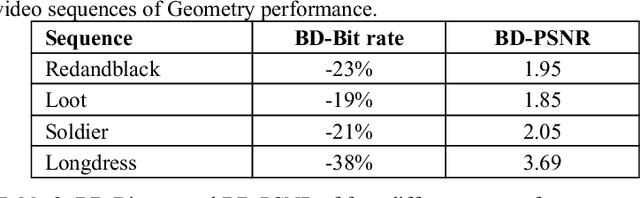

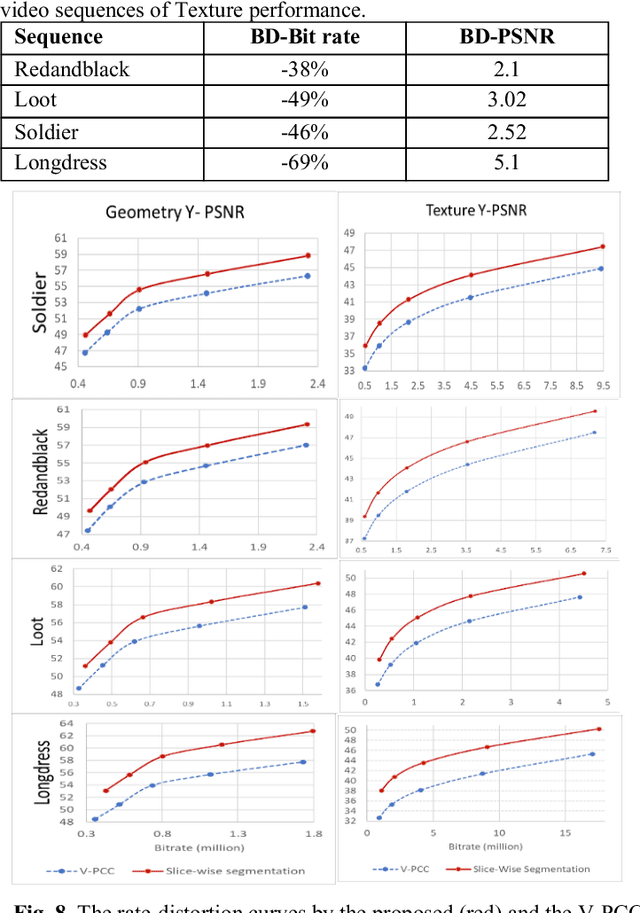
The recent development of dynamic point clouds has introduced the possibility of mimicking natural reality, and greatly assisting quality of life. However, to broadcast successfully, the dynamic point clouds require higher compression due to their huge volume of data compared to the traditional video. Recently, MPEG finalized a Video-based Point Cloud Compression standard known as V-PCC. However, V-PCC requires huge computational time due to expensive normal calculation and segmentation, sacrifices some points to limit the number of 2D patches, and cannot occupy all spaces in the 2D frame. The proposed method addresses these limitations by using a novel cross-sectional approach. This approach reduces expensive normal estimation and segmentation, retains more points, and utilizes more spaces for 2D frame generation compared to the VPCC. The experimental results using standard video sequences show that the proposed technique can achieve better compression in both geometric and texture data compared to the V-PCC standard.