 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-Domain Face Synthesis using a Controllable GAN
Oct 31, 2019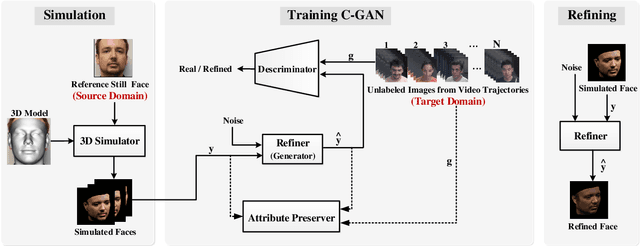
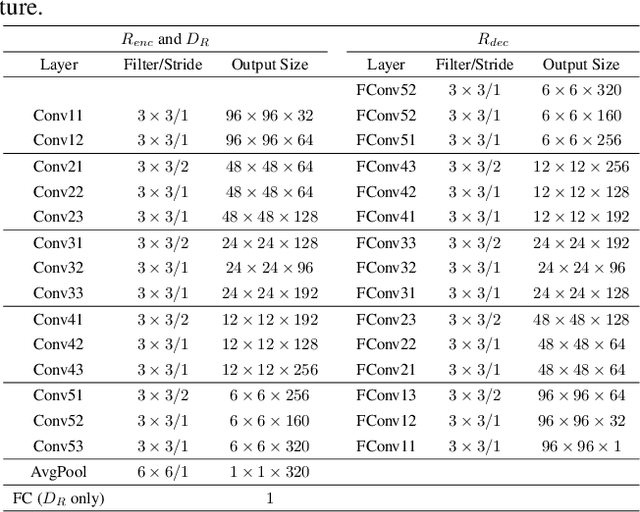
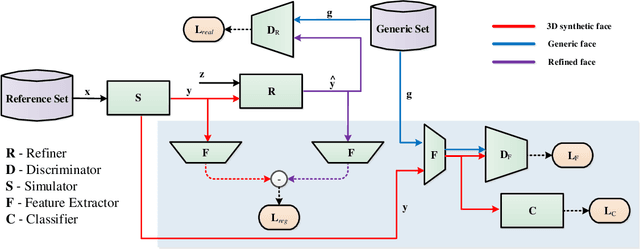
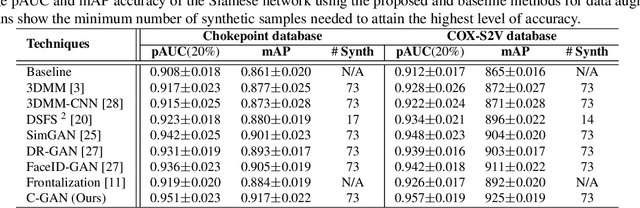
The performance of face recognition (FR) systems applied in video surveillance has been shown to improve when the design data is augmented through synthetic face generation. This is true, for instance, with pair-wise matchers (e.g., deep Siamese networks) that typically rely on a reference gallery with one still image per individual. However, generating synthetic images in the source domain may not improve the performance during operations due to the domain shift w.r.t. the target domain. Moreover, despite the emergence of Generative Adversarial Networks (GANs) for realistic synthetic generation, it is often difficult to control the conditions under which synthetic faces are generated. In this paper, a cross-domain face synthesis approach is proposed that integrates a new Controllable GAN (C-GAN). It employs an off-the-shelf 3D face model as a simulator to generate face images under various poses. The simulated images and noise are input to the C-GAN for realism refinement which employs an additional adversarial game as a third player to preserve the identity and specific facial attributes of the refined images. This allows generating realistic synthetic face images that reflects capture conditions in the target domain while controlling the GAN output to generate faces under desired pose conditions. Experiments were performed using videos from the Chokepoint and COX-S2V datasets, and a deep Siamese network for FR with a single reference still per person. Results indicate that the proposed approach can provide a higher level of accuracy compared to the current state-of-the-art approaches for synthetic data augmentation.
A Paired Sparse Representation Model for Robust Face Recognition from a Single Sample
Oct 05, 2019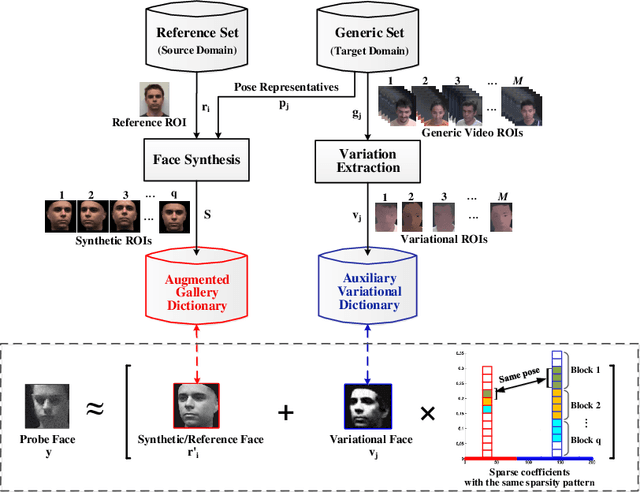

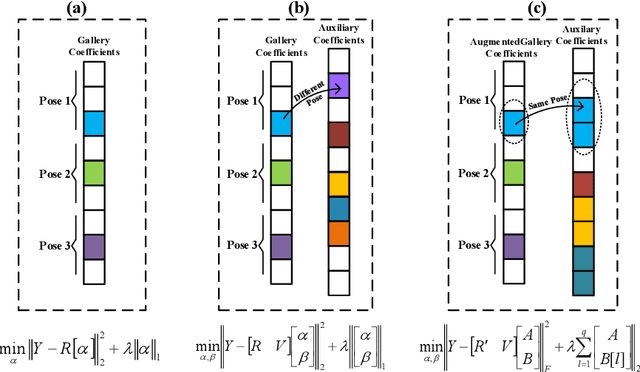
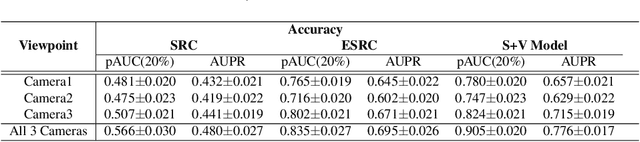
Sparse representation-based classification (SRC) has been shown to achieve a high level of accuracy in face recognition (FR). However, matching faces captured in unconstrained video against a gallery with a single reference facial still per individual typically yields low accuracy. For improved robustness to intra-class variations, SRC techniques for FR have recently been extended to incorporate variational information from an external generic set into an auxiliary dictionary. Despite their success in handling linear variations, non-linear variations (e.g., pose and expressions) between probe and reference facial images cannot be accurately reconstructed with a linear combination of images in the gallery and auxiliary dictionaries because they do not share the same type of variations. In order to account for non-linear variations due to pose, a paired sparse representation model is introduced allowing for joint use of variational information and synthetic face images. The proposed model, called synthetic plus variational model, reconstructs a probe image by jointly using (1) a variational dictionary and (2) a gallery dictionary augmented with a set of synthetic images generated over a wide diversity of pose angles. The augmented gallery dictionary is then encouraged to pair the same sparsity pattern with the variational dictionary for similar pose angles by solving a newly formulated simultaneous sparsity-based optimization problem. Experimental results obtained on Chokepoint and COX-S2V datasets, using different face representations, indicate that the proposed approach can outperform state-of-the-art SRC-based methods for still-to-video FR with a single sample per person.
Domain-Specific Face Synthesis for Video Face Recognition from a Single Sample Per Person
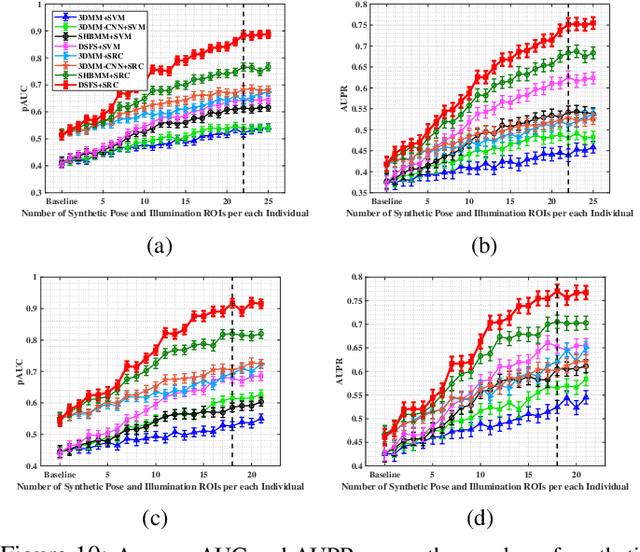
Oct 01, 2018
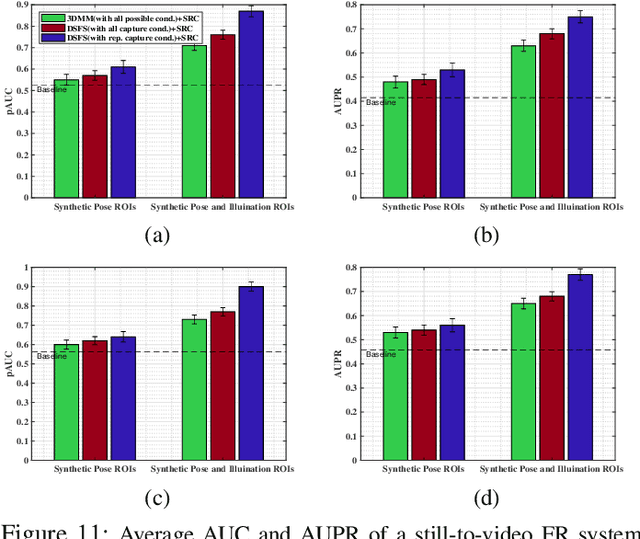

The performance of still-to-video FR systems can decline significantly because faces captured in unconstrained operational domain (OD) over multiple video cameras have a different underlying data distribution compared to faces captured under controlled conditions in the enrollment domain (ED) with a still camera. This is particularly true when individuals are enrolled to the system using a single reference still. To improve the robustness of these systems, it is possible to augment the reference set by generating synthetic faces based on the original still. However, without knowledge of the OD, many synthetic images must be generated to account for all possible capture conditions. FR systems may, therefore, require complex implementations and yield lower accuracy when training on many less relevant images. This paper introduces an algorithm for domain-specific face synthesis (DSFS) that exploits the representative intra-class variation information available from the OD. Prior to operation, a compact set of faces from unknown persons appearing in the OD is selected through clustering in the captured condition space. The domain-specific variations of these face images are projected onto the reference stills by integrating an image-based face relighting technique inside the 3D reconstruction framework. A compact set of synthetic faces is generated that resemble individuals of interest under the capture conditions relevant to the OD. In a particular implementation based on sparse representation classification, the synthetic faces generated with the DSFS are employed to form a cross-domain dictionary that account for structured sparsity. Experimental results reveal that augmenting the reference gallery set of FR systems using the proposed DSFS approach can provide a higher level of accuracy compared to state-of-the-art approaches, with only a moderate increase in its computational complexity.