 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomated Fake News Detection using cross-checking with reliable sources
Jan 01, 2022
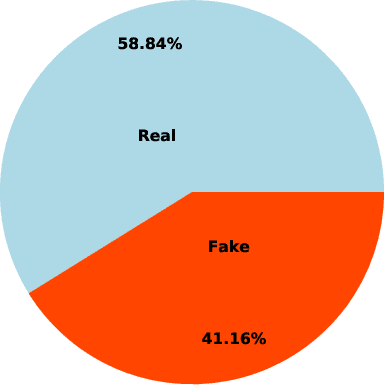
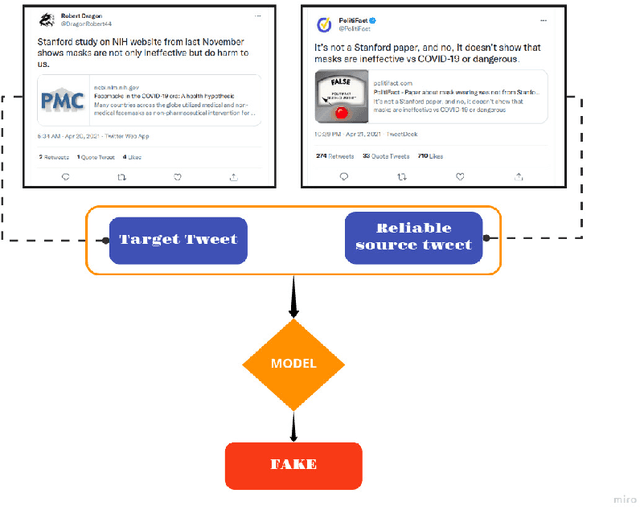
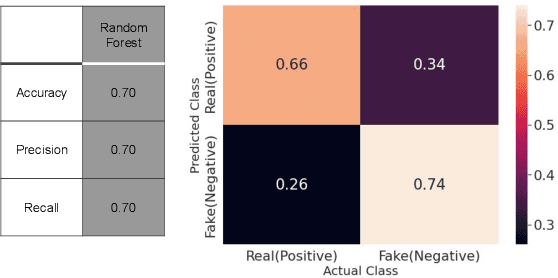
Over the past decade, fake news and misinformation have turned into a major problem that has impacted different aspects of our lives, including politics and public health. Inspired by natural human behavior, we present an approach that automates the detection of fake news. Natural human behavior is to cross-check new information with reliable sources. We use Natural Language Processing (NLP) and build a machine learning (ML) model that automates the process of cross-checking new information with a set of predefined reliable sources. We implement this for Twitter and build a model that flags fake tweets. Specifically, for a given tweet, we use its text to find relevant news from reliable news agencies. We then train a Random Forest model that checks if the textual content of the tweet is aligned with the trusted news. If it is not, the tweet is classified as fake. This approach can be generally applied to any kind of information and is not limited to a specific news story or a category of information. Our implementation of this approach gives a $70\%$ accuracy which outperforms other generic fake-news classification models. These results pave the way towards a more sensible and natural approach to fake news detection.
Extracting information from S-curves of language change
Oct 30, 2014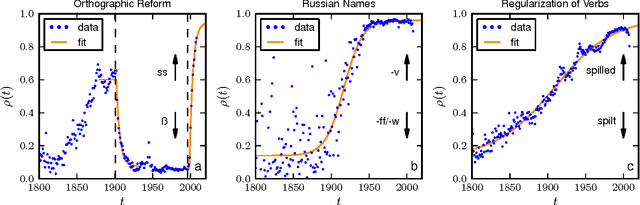
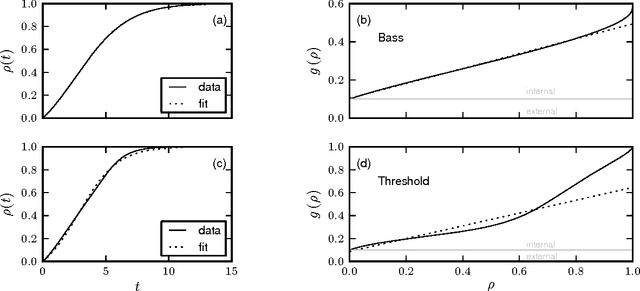
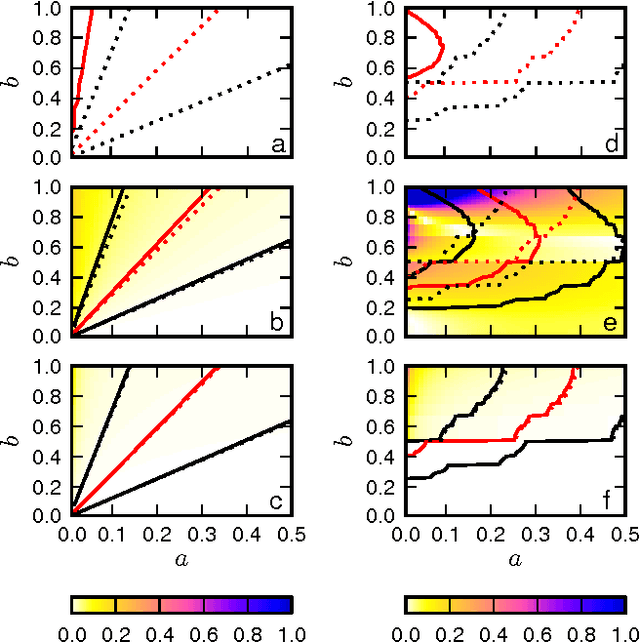
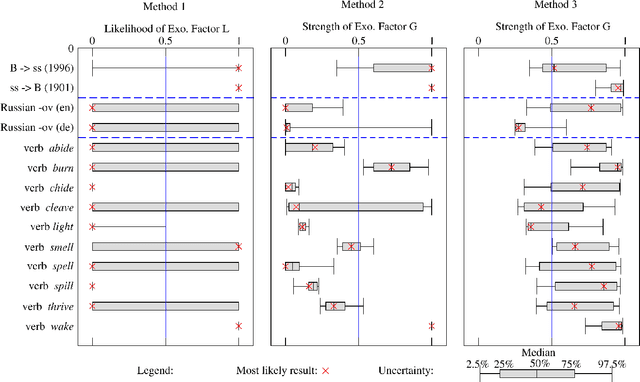
It is well accepted that adoption of innovations are described by S-curves (slow start, accelerating period, and slow end). In this paper, we analyze how much information on the dynamics of innovation spreading can be obtained from a quantitative description of S-curves. We focus on the adoption of linguistic innovations for which detailed databases of written texts from the last 200 years allow for an unprecedented statistical precision. Combining data analysis with simulations of simple models (e.g., the Bass dynamics on complex networks) we identify signatures of endogenous and exogenous factors in the S-curves of adoption. We propose a measure to quantify the strength of these factors and three different methods to estimate it from S-curves. We obtain cases in which the exogenous factors are dominant (in the adoption of German orthographic reforms and of one irregular verb) and cases in which endogenous factors are dominant (in the adoption of conventions for romanization of Russian names and in the regularization of most studied verbs). These results show that the shape of S-curve is not universal and contains information on the adoption mechanism. (published at "J. R. Soc. Interface, vol. 11, no. 101, (2014) 1044"; DOI: http://dx.doi.org/10.1098/rsif.2014.1044)
* 9 pages, 5 figures, Supplementary Material is available at http://dx.doi.org/10.6084/m9.figshare.1221782