 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Bayesian Framework of Deep Reinforcement Learning for Joint O-RAN/MEC Orchestration
Dec 26, 2023



Multi-access Edge Computing (MEC) can be implemented together with Open Radio Access Network (O-RAN) over commodity platforms to offer low-cost deployment and bring the services closer to end-users. In this paper, a joint O-RAN/MEC orchestration using a Bayesian deep reinforcement learning (RL)-based framework is proposed that jointly controls the O-RAN functional splits, the allocated resources and hosting locations of the O-RAN/MEC services across geo-distributed platforms, and the routing for each O-RAN/MEC data flow. The goal is to minimize the long-term overall network operation cost and maximize the MEC performance criterion while adapting possibly time-varying O-RAN/MEC demands and resource availability. This orchestration problem is formulated as Markov decision process (MDP). However, the system consists of multiple BSs that share the same resources and serve heterogeneous demands, where their parameters have non-trivial relations. Consequently, finding the exact model of the underlying system is impractical, and the formulated MDP renders in a large state space with multi-dimensional discrete action. To address such modeling and dimensionality issues, a novel model-free RL agent is proposed for our solution framework. The agent is built from Double Deep Q-network (DDQN) that tackles the large state space and is then incorporated with action branching, an action decomposition method that effectively addresses the multi-dimensional discrete action with linear increase complexity. Further, an efficient exploration-exploitation strategy under a Bayesian framework using Thomson sampling is proposed to improve the learning performance and expedite its convergence. Trace-driven simulations are performed using an O-RAN-compliant model. The results show that our approach is data-efficient (i.e., converges faster) and increases the returned reward by 32\% than its non-Bayesian version.
Constrained Deep Reinforcement Based Functional Split Optimization in Virtualized RANs
May 31, 2021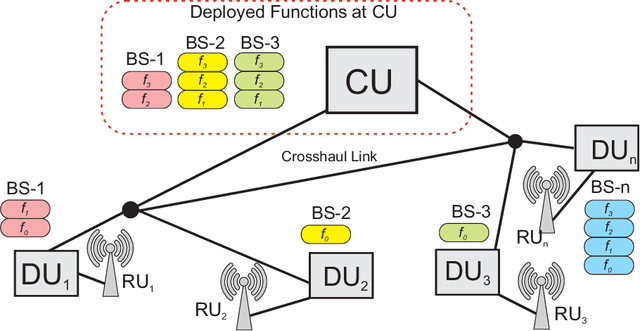
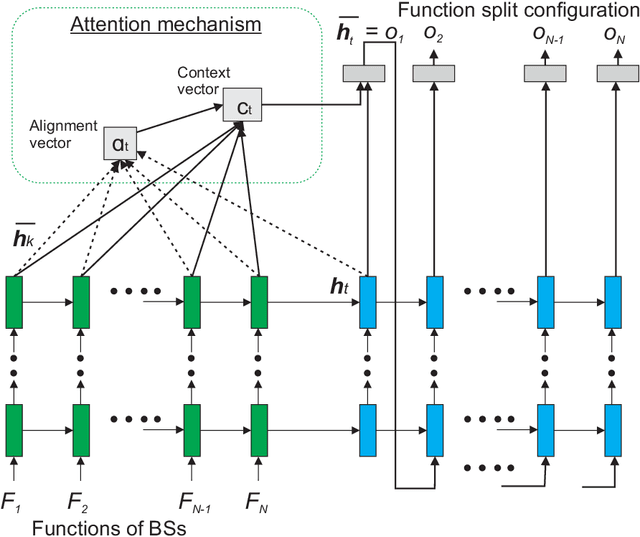
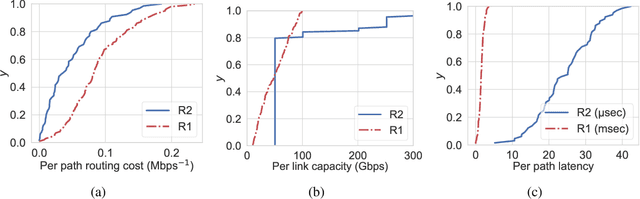
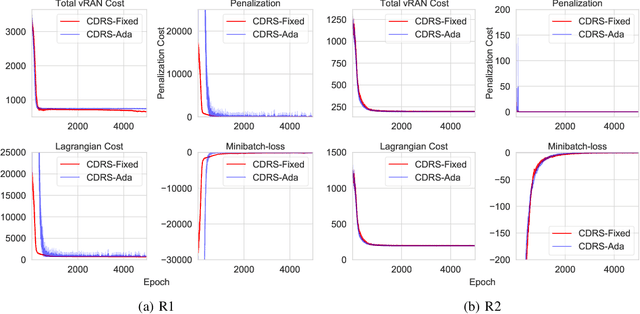
Virtualized Radio Access Network (vRAN) brings agility to Next-Generation RAN through functional split. It allows decomposing the base station (BS) functions into virtualized components and hosts it either at the distributed-unit (DU) or central-unit (CU). However, deciding which functions to deploy at DU or CU to minimize the total network cost is challenging. In this paper, a constrained deep reinforcement based functional split optimization (CDRS) is proposed to optimize the locations of functions in vRAN. Our formulation results in a combinatorial and NP-hard problem for which finding the exact solution is computationally expensive. Hence, in our proposed approach, a policy gradient method with Lagrangian relaxation is applied that uses a penalty signal to lead the policy toward constraint satisfaction. It utilizes a neural network architecture formed by an encoder-decoder sequence-to-sequence model based on stacked Long Short-term Memory (LSTM) networks to approximate the policy. Greedy decoding and temperature sampling methods are also leveraged for a search strategy to infer the best solution among candidates from multiple trained models that help to avoid a severe suboptimality. Simulations are performed to evaluate the performance of the proposed solution in both synthetic and real network datasets. Our findings reveal that CDRS successfully learns the optimal decision, solves the problem with the accuracy of 0.05\% optimality gap and becomes the most cost-effective compared to the available RAN setups. Moreover, altering the routing cost and traffic load does not significantly degrade the optimality. The results also show that all of our CDRS settings have faster computational time than the optimal baseline solver. Our proposed method fills the gap of optimizing the functional split offering a near-optimal solution, faster computational time and minimal hand-engineering.