 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDL-EWF: Deep Learning Empowering Women's Fashion with Grounded-Segment-Anything Segmentation for Body Shape Classification
Apr 07, 2024The global fashion industry plays a pivotal role in the global economy, and addressing fundamental issues within the industry is crucial for developing innovative solutions. One of the most pressing challenges in the fashion industry is the mismatch between body shapes and the garments of individuals they purchase. This issue is particularly prevalent among individuals with non-ideal body shapes, exacerbating the challenges faced. Considering inter-individual variability in body shapes is essential for designing and producing garments that are widely accepted by consumers. Traditional methods for determining human body shape are limited due to their low accuracy, high costs, and time-consuming nature. New approaches, utilizing digital imaging and deep neural networks (DNN), have been introduced to identify human body shape. In this study, the Style4BodyShape dataset is used for classifying body shapes into five categories: Rectangle, Triangle, Inverted Triangle, Hourglass, and Apple. In this paper, the body shape segmentation of a person is extracted from the image, disregarding the surroundings and background. Then, Various pre-trained models, such as ResNet18, ResNet34, ResNet50, VGG16, VGG19, and Inception v3, are used to classify the segmentation results. Among these pre-trained models, the Inception V3 model demonstrates superior performance regarding f1-score evaluation metric and accuracy compared to the other models.
cycle text2face: cycle text-to-face gan via transformers
Jun 09, 2022

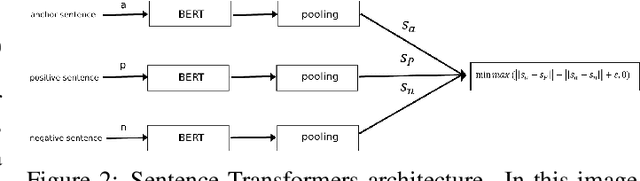

Text-to-face is a subset of text-to-image that require more complex architecture due to their more detailed production. In this paper, we present an encoder-decoder model called Cycle Text2Face. Cycle Text2Face is a new initiative in the encoder part, it uses a sentence transformer and GAN to generate the image described by the text. The Cycle is completed by reproducing the text of the face in the decoder part of the model. Evaluating the model using the CelebA dataset, leads to better results than previous GAN-based models. In measuring the quality of the generate face, in addition to satisfying the human audience, we obtain an FID score of 3.458. This model, with high-speed processing, provides quality face images in the short time.