Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgecycle text2face: cycle text-to-face gan via transformers
Paper and Code
Jun 09, 2022

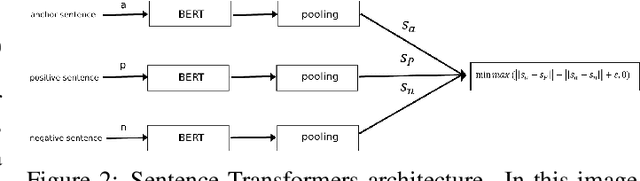

Text-to-face is a subset of text-to-image that require more complex architecture due to their more detailed production. In this paper, we present an encoder-decoder model called Cycle Text2Face. Cycle Text2Face is a new initiative in the encoder part, it uses a sentence transformer and GAN to generate the image described by the text. The Cycle is completed by reproducing the text of the face in the decoder part of the model. Evaluating the model using the CelebA dataset, leads to better results than previous GAN-based models. In measuring the quality of the generate face, in addition to satisfying the human audience, we obtain an FID score of 3.458. This model, with high-speed processing, provides quality face images in the short time.
View paper on