 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploiting Sentence-Level Representations for Passage Ranking
Jun 14, 2021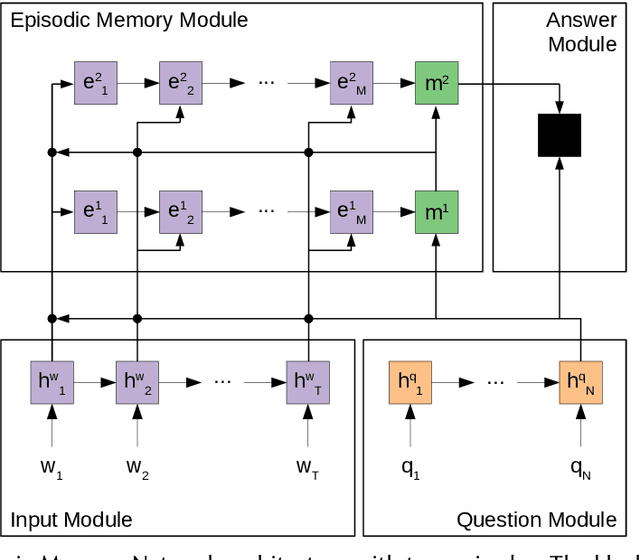
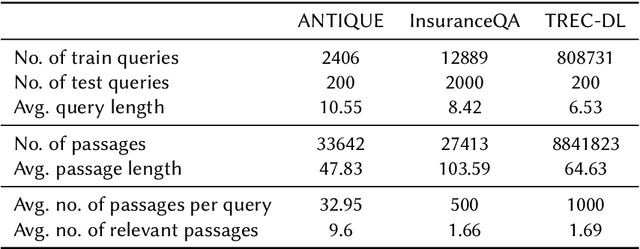
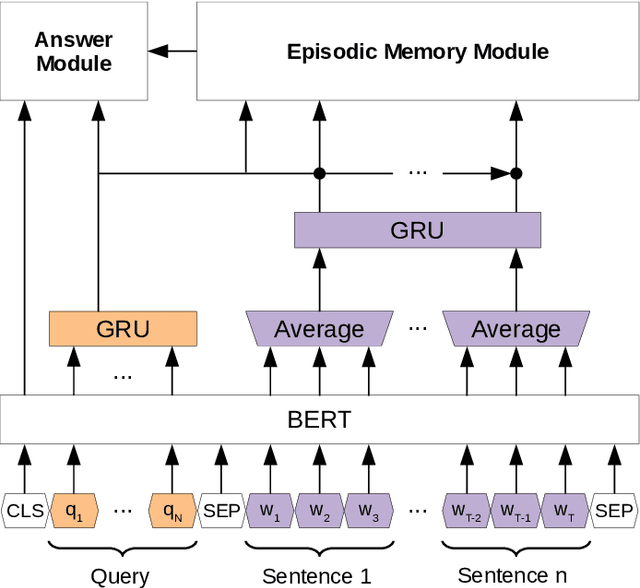
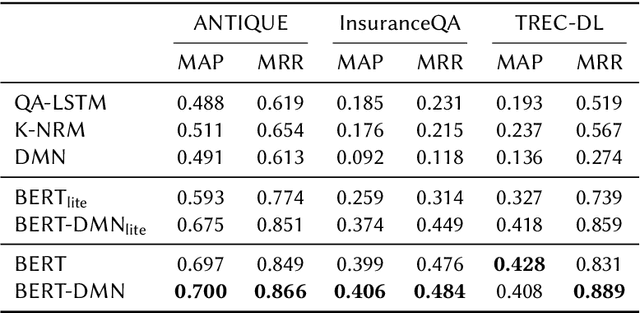
Recently, pre-trained contextual models, such as BERT, have shown to perform well in language related tasks. We revisit the design decisions that govern the applicability of these models for the passage re-ranking task in open-domain question answering. We find that common approaches in the literature rely on fine-tuning a pre-trained BERT model and using a single, global representation of the input, discarding useful fine-grained relevance signals in token- or sentence-level representations. We argue that these discarded tokens hold useful information that can be leveraged. In this paper, we explicitly model the sentence-level representations by using Dynamic Memory Networks (DMNs) and conduct empirical evaluation to show improvements in passage re-ranking over fine-tuned vanilla BERT models by memory-enhanced explicit sentence modelling on a diverse set of open-domain QA datasets. We further show that freezing the BERT model and only training the DMN layer still comes close to the original performance, while improving training efficiency drastically. This indicates that the usual fine-tuning step mostly helps to aggregate the inherent information in a single output token, as opposed to adapting the whole model to the new task, and only achieves rather small gains.