 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGreen or Fast? Learning to Balance Cold Starts and Idle Carbon in Serverless Computing
Feb 27, 2026Serverless computing simplifies cloud deployment but introduces new challenges in managing service latency and carbon emissions. Reducing cold-start latency requires retaining warm function instances, while minimizing carbon emissions favors reclaiming idle resources. This balance is further complicated by time-varying grid carbon intensity and varying workload patterns, under which static keep-alive policies are inefficient. We present LACE-RL, a latency-aware and carbon-efficient management framework that formulates serverless pod retention as a sequential decision problem. LACE-RL uses deep reinforcement learning to dynamically tune keep-alive durations, jointly modeling cold-start probability, function-specific latency costs, and real-time carbon intensity. Using the Huawei Public Cloud Trace, we show that LACE-RL reduces cold starts by 51.69% and idle keep-alive carbon emissions by 77.08% compared to Huawei's static policy, while achieving better latency-carbon trade-offs than state-of-the-art heuristic and single-objective baselines, approaching Oracle performance.
Black-box Adversarial Attacks on CNN-based SLAM Algorithms
May 30, 2025Continuous advancements in deep learning have led to significant progress in feature detection, resulting in enhanced accuracy in tasks like Simultaneous Localization and Mapping (SLAM). Nevertheless, the vulnerability of deep neural networks to adversarial attacks remains a challenge for their reliable deployment in applications, such as navigation of autonomous agents. Even though CNN-based SLAM algorithms are a growing area of research there is a notable absence of a comprehensive presentation and examination of adversarial attacks targeting CNN-based feature detectors, as part of a SLAM system. Our work introduces black-box adversarial perturbations applied to the RGB images fed into the GCN-SLAM algorithm. Our findings on the TUM dataset [30] reveal that even attacks of moderate scale can lead to tracking failure in as many as 76% of the frames. Moreover, our experiments highlight the catastrophic impact of attacking depth instead of RGB input images on the SLAM system.
The Life and Death of SSDs and HDDs: Similarities, Differences, and Prediction Models
Dec 22, 2020
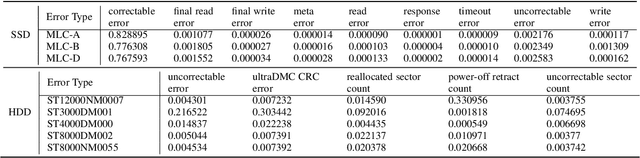


Data center downtime typically centers around IT equipment failure. Storage devices are the most frequently failing components in data centers. We present a comparative study of hard disk drives (HDDs) and solid state drives (SSDs) that constitute the typical storage in data centers. Using a six-year field data of 100,000 HDDs of different models from the same manufacturer from the BackBlaze dataset and a six-year field data of 30,000 SSDs of three models from a Google data center, we characterize the workload conditions that lead to failures and illustrate that their root causes differ from common expectation but remain difficult to discern. For the case of HDDs we observe that young and old drives do not present many differences in their failures. Instead, failures may be distinguished by discriminating drives based on the time spent for head positioning. For SSDs, we observe high levels of infant mortality and characterize the differences between infant and non-infant failures. We develop several machine learning failure prediction models that are shown to be surprisingly accurate, achieving high recall and low false positive rates. These models are used beyond simple prediction as they aid us to untangle the complex interaction of workload characteristics that lead to failures and identify failure root causes from monitored symptoms.