 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards True Detail Restoration for Super-Resolution: A Benchmark and a Quality Metric
Mar 16, 2022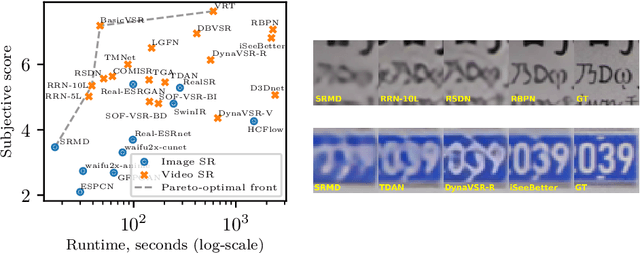
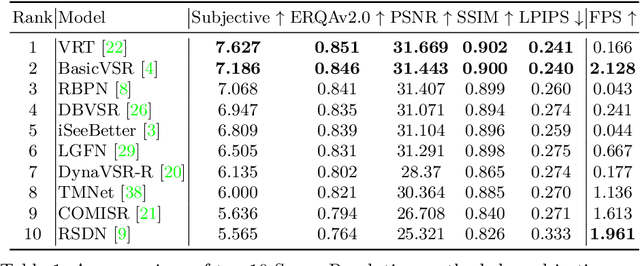

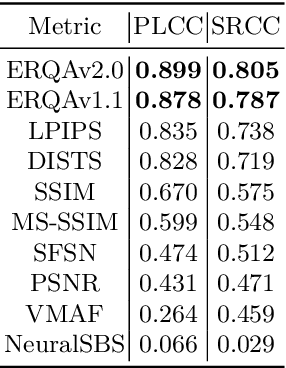
Super-resolution (SR) has become a widely researched topic in recent years. SR methods can improve overall image and video quality and create new possibilities for further content analysis. But the SR mainstream focuses primarily on increasing the naturalness of the resulting image despite potentially losing context accuracy. Such methods may produce an incorrect digit, character, face, or other structural object even though they otherwise yield good visual quality. Incorrect detail restoration can cause errors when detecting and identifying objects both manually and automatically. To analyze the detail-restoration capabilities of image and video SR models, we developed a benchmark based on our own video dataset, which contains complex patterns that SR models generally fail to correctly restore. We assessed 32 recent SR models using our benchmark and compared their ability to preserve scene context. We also conducted a crowd-sourced comparison of restored details and developed an objective assessment metric that outperforms other quality metrics by correlation with subjective scores for this task. In conclusion, we provide a deep analysis of benchmark results that yields insights for future SR-based work.