 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScalable and Robust Transformer Decoders for Interpretable Image Classification with Foundation Models
Mar 07, 2024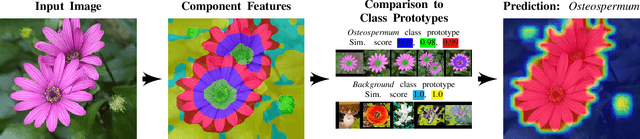
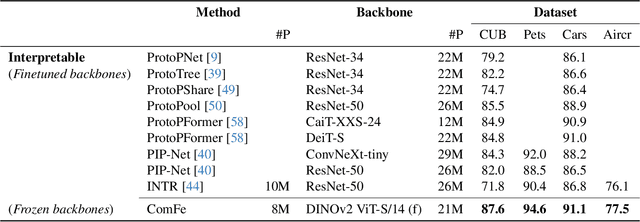
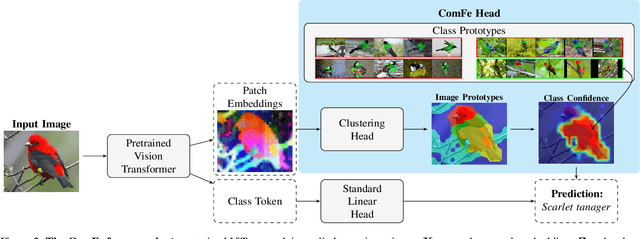
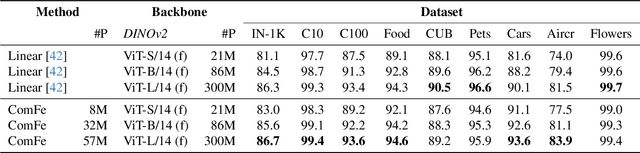
Interpretable computer vision models can produce transparent predictions, where the features of an image are compared with prototypes from a training dataset and the similarity between them forms a basis for classification. Nevertheless these methods are computationally expensive to train, introduce additional complexity and may require domain knowledge to adapt hyper-parameters to a new dataset. Inspired by developments in object detection, segmentation and large-scale self-supervised foundation vision models, we introduce Component Features (ComFe), a novel explainable-by-design image classification approach using a transformer-decoder head and hierarchical mixture-modelling. With only global image labels and no segmentation or part annotations, ComFe can identify consistent image components, such as the head, body, wings and tail of a bird, and the image background, and determine which of these features are informative in making a prediction. We demonstrate that ComFe obtains higher accuracy compared to previous interpretable models across a range of fine-grained vision benchmarks, without the need to individually tune hyper-parameters for each dataset. We also show that ComFe outperforms a non-interpretable linear head across a range of datasets, including ImageNet, and improves performance on generalisation and robustness benchmarks.
Detecting and recognizing characters in Greek papyri with YOLOv8, DeiT and SimCLR
Jan 23, 2024The capacity to isolate and recognize individual characters from facsimile images of papyrus manuscripts yields rich opportunities for digital analysis. For this reason the `ICDAR 2023 Competition on Detection and Recognition of Greek Letters on Papyri' was held as part of the 17th International Conference on Document Analysis and Recognition. This paper discusses our submission to the competition. We used an ensemble of YOLOv8 models to detect and classify individual characters and employed two different approaches for refining the character predictions, including a transformer based DeiT approach and a ResNet-50 model trained on a large corpus of unlabelled data using SimCLR, a self-supervised learning method. Our submission won the recognition challenge with a mAP of 42.2%, and was runner-up in the detection challenge with a mean average precision (mAP) of 51.4%. At the more relaxed intersection over union threshold of 0.5, we achieved the highest mean average precision and mean average recall results for both detection and classification. We ran our prediction pipeline on more than 4,500 images from the Oxyrhynchus Papyri to illustrate the utility of our approach, and we release the results publicly in multiple formats.
Improved Prototypical Semi-Supervised Learning with Foundation Models: Prototype Selection, Parametric vMF-SNE Pretraining and Multi-view Pseudolabelling
Nov 28, 2023In this paper we present an improved approach to prototypical semi-supervised learning for computer vision, in the context of leveraging a frozen foundation model as the backbone of our neural network. As a general tool, we propose parametric von-Mises Fisher Stochastic Neighbour Embedding (vMF-SNE) to create mappings with neural networks between high-dimensional latent spaces that preserve local structure. This enables us to pretrain the projection head of our network using the high-quality embeddings of the foundation model with vMF-SNE. We also propose soft multi-view pseudolabels, where predictions across multiple views are combined to provide a more reliable supervision signal compared to a consistency or swapped assignment approach. We demonstrate that these ideas improve upon P}redicting View-Assignments with Support Samples (PAWS), a current state-of-the-art semi-supervised learning method, as well as Robust PAWS (RoPAWS), over a range of benchmarking datasets. We also introduce simple $k$-means prototype selection, a technique that provides superior performance to other unsupervised label selection approaches in this context. These changes improve upon PAWS by an average of +2.9% for CIFAR-10 and +5.7% for CIFAR-100 with four labels per class, and by +15.2% for DeepWeeds, a particularly challenging dataset for semi-supervised learning. We also achieve new state-of-the-art results in semi-supervised learning in this small label regime for CIFAR-10 - 95.8% (+0.7%) and CIFAR-100 - 76.6% (+12.0%).