 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScalable and Robust Transformer Decoders for Interpretable Image Classification with Foundation Models
Paper and Code
Mar 07, 2024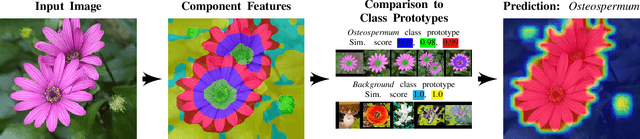
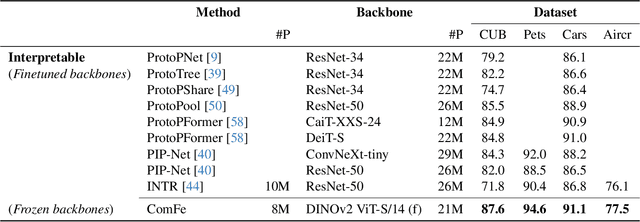
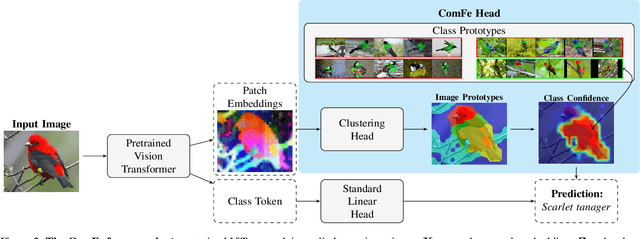
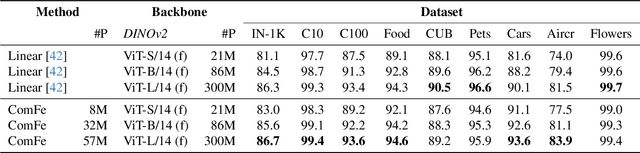
Interpretable computer vision models can produce transparent predictions, where the features of an image are compared with prototypes from a training dataset and the similarity between them forms a basis for classification. Nevertheless these methods are computationally expensive to train, introduce additional complexity and may require domain knowledge to adapt hyper-parameters to a new dataset. Inspired by developments in object detection, segmentation and large-scale self-supervised foundation vision models, we introduce Component Features (ComFe), a novel explainable-by-design image classification approach using a transformer-decoder head and hierarchical mixture-modelling. With only global image labels and no segmentation or part annotations, ComFe can identify consistent image components, such as the head, body, wings and tail of a bird, and the image background, and determine which of these features are informative in making a prediction. We demonstrate that ComFe obtains higher accuracy compared to previous interpretable models across a range of fine-grained vision benchmarks, without the need to individually tune hyper-parameters for each dataset. We also show that ComFe outperforms a non-interpretable linear head across a range of datasets, including ImageNet, and improves performance on generalisation and robustness benchmarks.