 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMinibatch Optimal Transport and Perplexity Bound Estimation in Discrete Flow Matching
Nov 01, 2024Outperforming autoregressive models on categorical data distributions, such as textual data, remains challenging for continuous diffusion and flow models. Discrete flow matching, a recent framework for modeling categorical data, has shown competitive performance with autoregressive models. Despite its similarities with continuous flow matching, the rectification strategy applied in the continuous version does not directly extend to the discrete one due to the inherent stochasticity of discrete paths. This limitation necessitates exploring alternative methods to minimize state transitions during generation. To address this, we propose a dynamic-optimal-transport-like minimization objective for discrete flows with convex interpolants and derive its equivalent Kantorovich formulation. The latter defines transport cost solely in terms of inter-state similarity and is optimized using a minibatch strategy. Another limitation we address in the discrete flow framework is model evaluation. Unlike continuous flows, wherein the instantaneous change of variables enables density estimation, discrete models lack a similar mechanism due to the inherent non-determinism and discontinuity of their paths. To alleviate this issue, we propose an upper bound on the perplexity of discrete flow models, enabling performance evaluation and comparison with other methods.
Faster Training of Diffusion Models and Improved Density Estimation via Parallel Score Matching
Jun 05, 2023In Diffusion Probabilistic Models (DPMs), the task of modeling the score evolution via a single time-dependent neural network necessitates extended training periods and may potentially impede modeling flexibility and capacity. To counteract these challenges, we propose leveraging the independence of learning tasks at different time points inherent to DPMs. More specifically, we partition the learning task by utilizing independent networks, each dedicated to learning the evolution of scores within a specific time sub-interval. Further, inspired by residual flows, we extend this strategy to its logical conclusion by employing separate networks to independently model the score at each individual time point. As empirically demonstrated on synthetic and image datasets, our approach not only significantly accelerates the training process by introducing an additional layer of parallelization atop data parallelization, but it also enhances density estimation performance when compared to the conventional training methodology for DPMs.
Enhanced Distribution Modelling via Augmented Architectures For Neural ODE Flows
Jun 05, 2023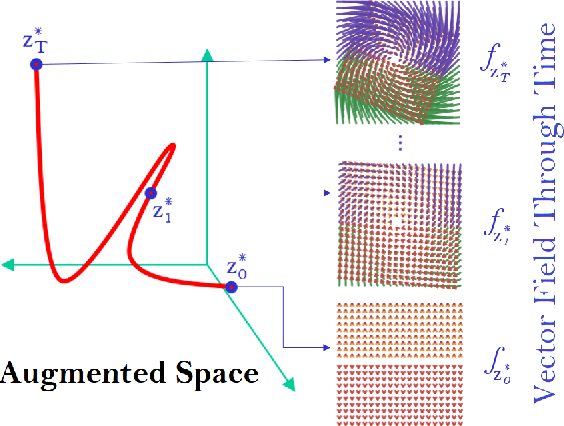

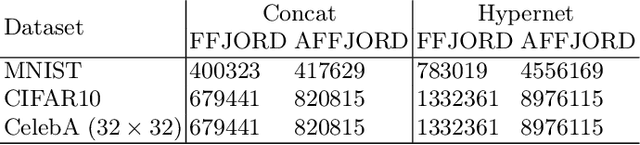
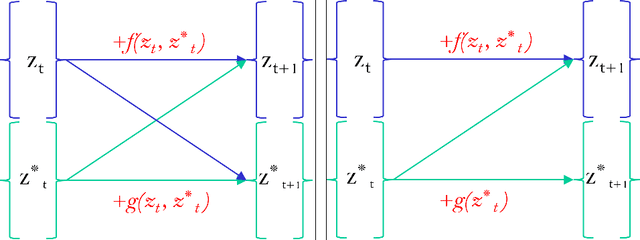
While the neural ODE formulation of normalizing flows such as in FFJORD enables us to calculate the determinants of free form Jacobians in O(D) time, the flexibility of the transformation underlying neural ODEs has been shown to be suboptimal. In this paper, we present AFFJORD, a neural ODE-based normalizing flow which enhances the representation power of FFJORD by defining the neural ODE through special augmented transformation dynamics which preserve the topology of the space. Furthermore, we derive the Jacobian determinant of the general augmented form by generalizing the chain rule in the continuous sense into the Cable Rule, which expresses the forward sensitivity of ODEs with respect to their initial conditions. The cable rule gives an explicit expression for the Jacobian of a neural ODE transformation, and provides an elegant proof of the instantaneous change of variable. Our experimental results on density estimation in synthetic and high dimensional data, such as MNIST, CIFAR-10 and CelebA 32x32, show that AFFJORD outperforms the baseline FFJORD through the improved flexibility of the underlying vector field.
On Tail Decay Rate Estimation of Loss Function Distributions
Jun 05, 2023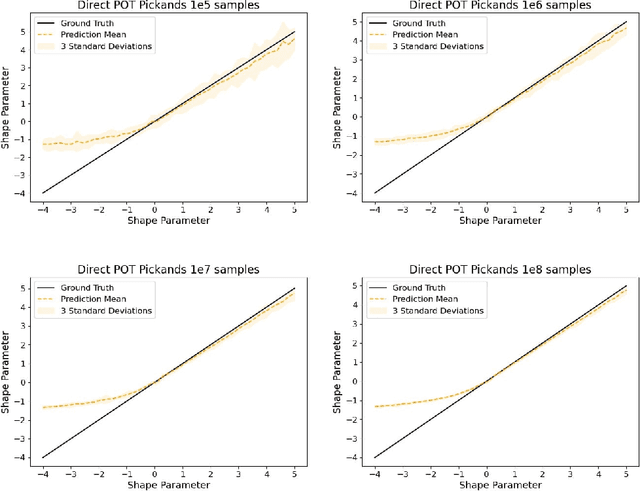
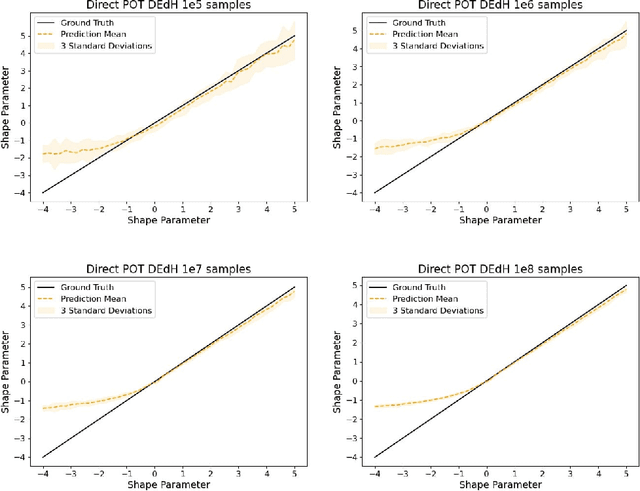
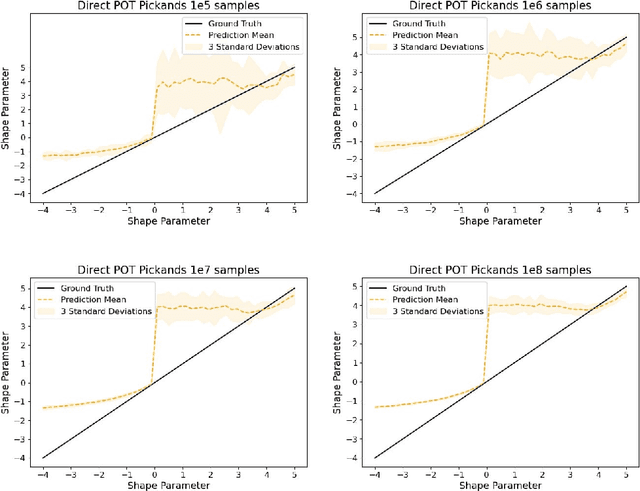
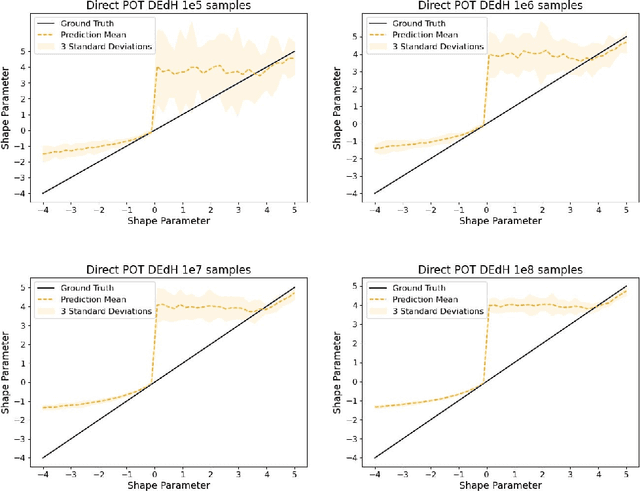
The study of loss function distributions is critical to characterize a model's behaviour on a given machine learning problem. For example, while the quality of a model is commonly determined by the average loss assessed on a testing set, this quantity does not reflect the existence of the true mean of the loss distribution. Indeed, the finiteness of the statistical moments of the loss distribution is related to the thickness of its tails, which are generally unknown. Since typical cross-validation schemes determine a family of testing loss distributions conditioned on the training samples, the total loss distribution must be recovered by marginalizing over the space of training sets. As we show in this work, the finiteness of the sampling procedure negatively affects the reliability and efficiency of classical tail estimation methods from the Extreme Value Theory, such as the Peaks-Over-Threshold approach. In this work we tackle this issue by developing a novel general theory for estimating the tails of marginal distributions, when there exists a large variability between locations of the individual conditional distributions underlying the marginal. To this end, we demonstrate that under some regularity conditions, the shape parameter of the marginal distribution is the maximum tail shape parameter of the family of conditional distributions. We term this estimation approach as Cross Tail Estimation (CTE). We test cross-tail estimation in a series of experiments on simulated and real data, showing the improved robustness and quality of tail estimation as compared to classical approaches, and providing evidence for the relationship between overfitting and loss distribution tail thickness.