 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Repulsive Prototypes for Adversarial Robustness
May 26, 2021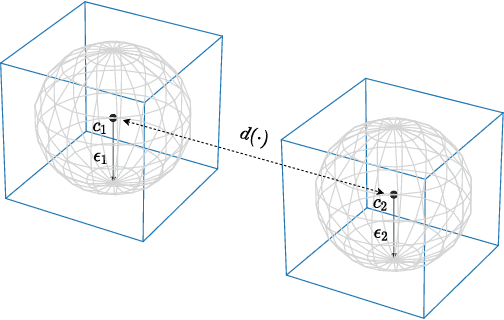
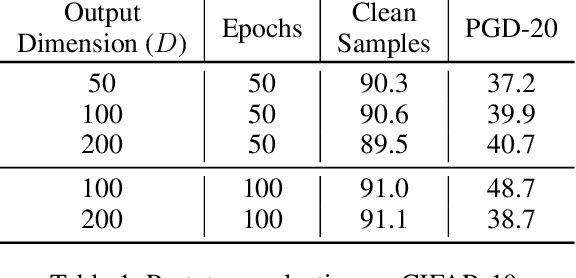
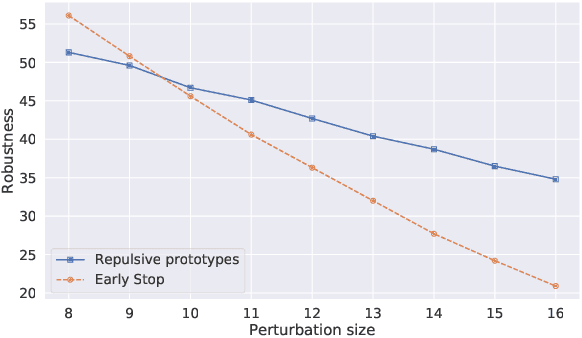
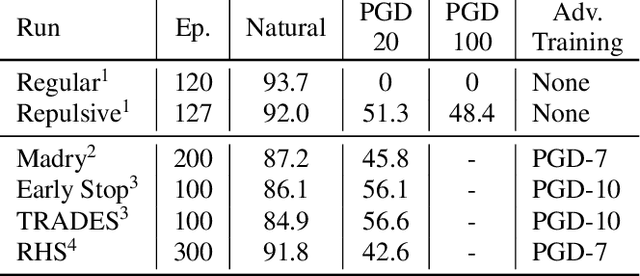
While many defences against adversarial examples have been proposed, finding robust machine learning models is still an open problem. The most compelling defence to date is adversarial training and consists of complementing the training data set with adversarial examples. Yet adversarial training severely impacts training time and depends on finding representative adversarial samples. In this paper we propose to train models on output spaces with large class separation in order to gain robustness without adversarial training. We introduce a method to partition the output space into class prototypes with large separation and train models to preserve it. Experimental results shows that models trained with these prototypes -- which we call deep repulsive prototypes -- gain robustness competitive with adversarial training, while also preserving more accuracy on natural samples. Moreover, the models are more resilient to large perturbation sizes. For example, we obtained over 50% robustness for CIFAR-10, with 92% accuracy on natural samples and over 20% robustness for CIFAR-100, with 71% accuracy on natural samples without adversarial training. For both data sets, the models preserved robustness against large perturbations better than adversarially trained models.
Adversarial Examples on Object Recognition: A Comprehensive Survey
Sep 03, 2020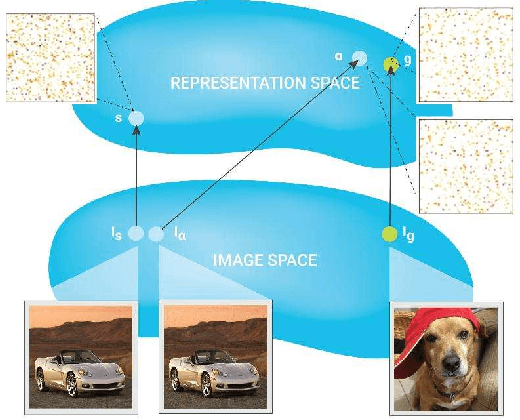
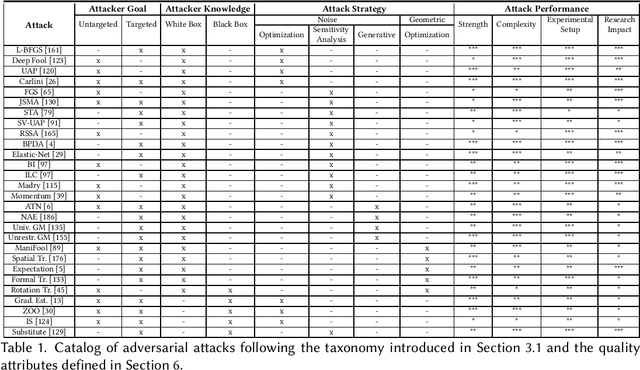
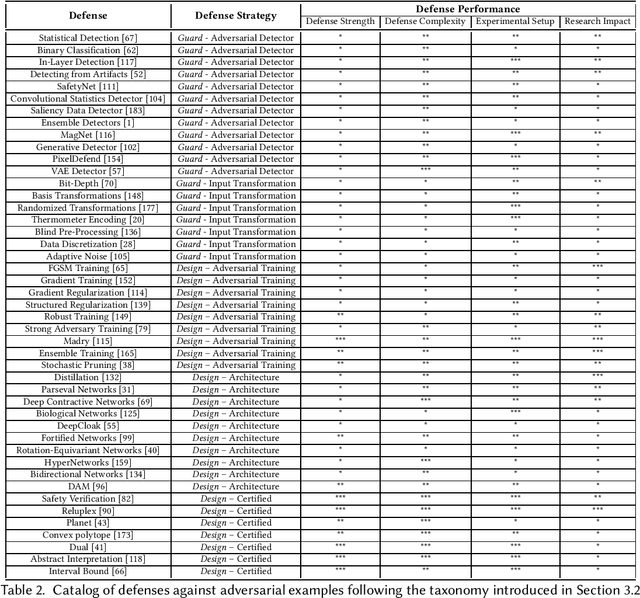

Deep neural networks are at the forefront of machine learning research. However, despite achieving impressive performance on complex tasks, they can be very sensitive: Small perturbations of inputs can be sufficient to induce incorrect behavior. Such perturbations, called adversarial examples, are intentionally designed to test the network's sensitivity to distribution drifts. Given their surprisingly small size, a wide body of literature conjectures on their existence and how this phenomenon can be mitigated. In this article we discuss the impact of adversarial examples on security, safety, and robustness of neural networks. We start by introducing the hypotheses behind their existence, the methods used to construct or protect against them, and the capacity to transfer adversarial examples between different machine learning models. Altogether, the goal is to provide a comprehensive and self-contained survey of this growing field of research.
Learning to Learn from Mistakes: Robust Optimization for Adversarial Noise
Aug 12, 2020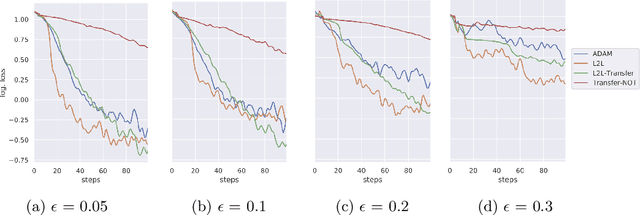
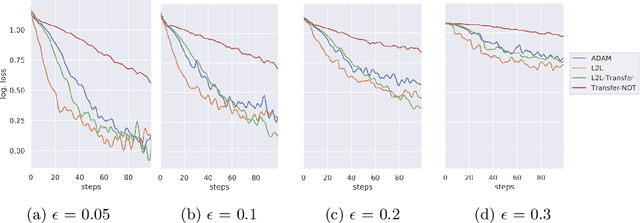
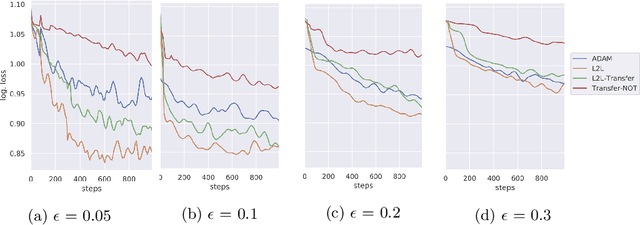
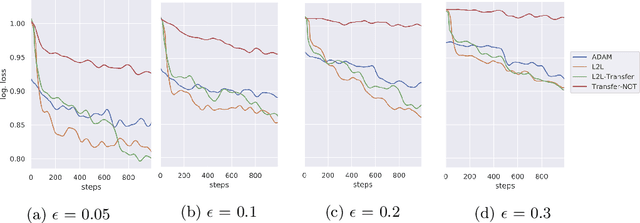
Sensitivity to adversarial noise hinders deployment of machine learning algorithms in security-critical applications. Although many adversarial defenses have been proposed, robustness to adversarial noise remains an open problem. The most compelling defense, adversarial training, requires a substantial increase in processing time and it has been shown to overfit on the training data. In this paper, we aim to overcome these limitations by training robust models in low data regimes and transfer adversarial knowledge between different models. We train a meta-optimizer which learns to robustly optimize a model using adversarial examples and is able to transfer the knowledge learned to new models, without the need to generate new adversarial examples. Experimental results show the meta-optimizer is consistent across different architectures and data sets, suggesting it is possible to automatically patch adversarial vulnerabilities.
Adversarial Examples - A Complete Characterisation of the Phenomenon
Oct 02, 2018
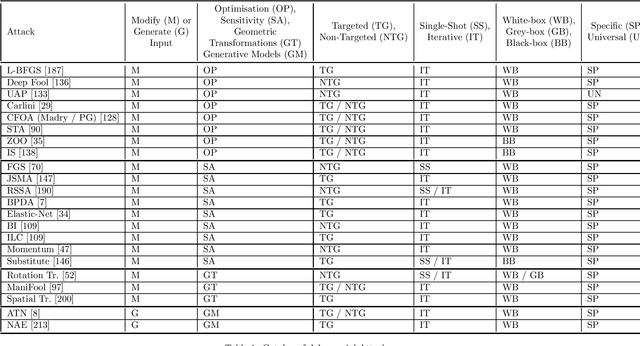
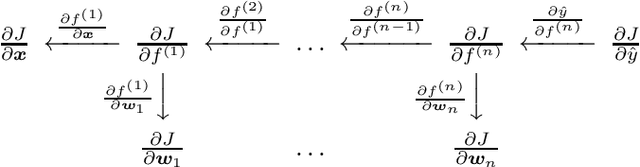
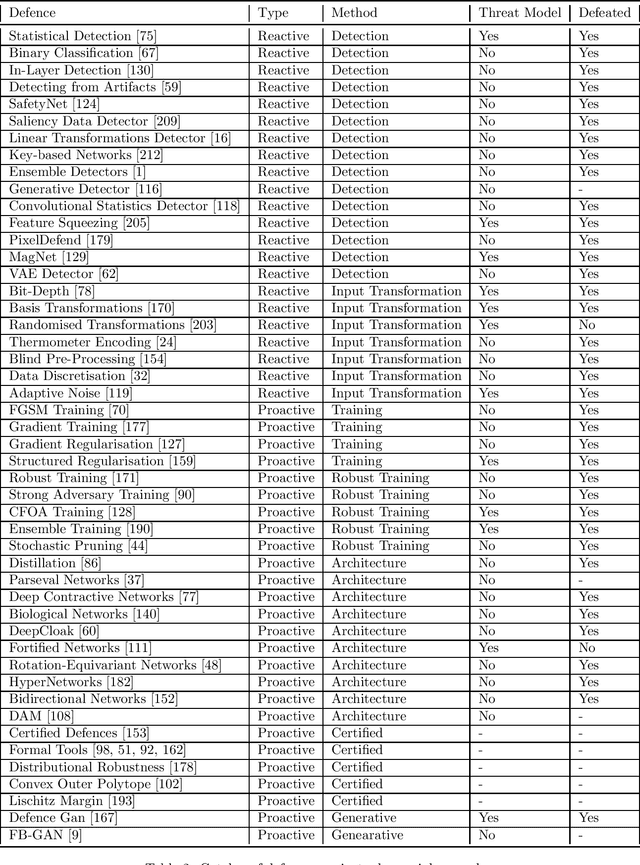
We provide a complete characterisation of the phenomenon of adversarial examples - inputs intentionally crafted to fool machine learning models. We aim to cover all the important concerns in this field of study: (1) the conjectures on the existence of adversarial examples, (2) the security, safety and robustness implications, (3) the methods used to generate and (4) protect against adversarial examples and (5) the ability of adversarial examples to transfer between different machine learning models. We provide ample background information in an effort to make this document self-contained. Therefore, this document can be used as survey, tutorial or as a catalog of attacks and defences using adversarial examples.