 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdversarial Examples on Object Recognition: A Comprehensive Survey
Paper and Code
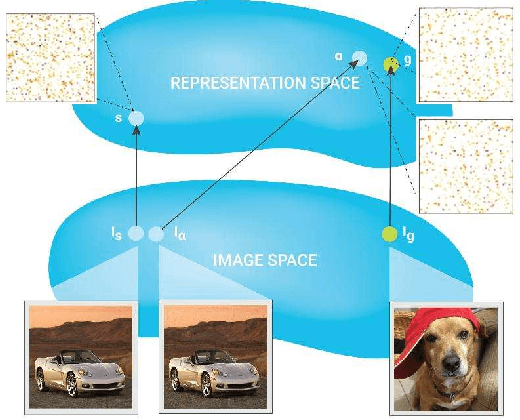
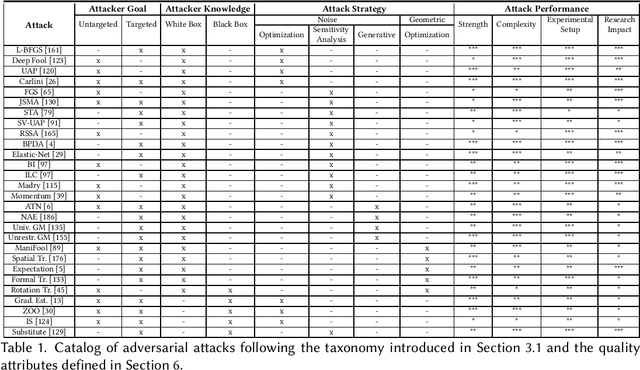
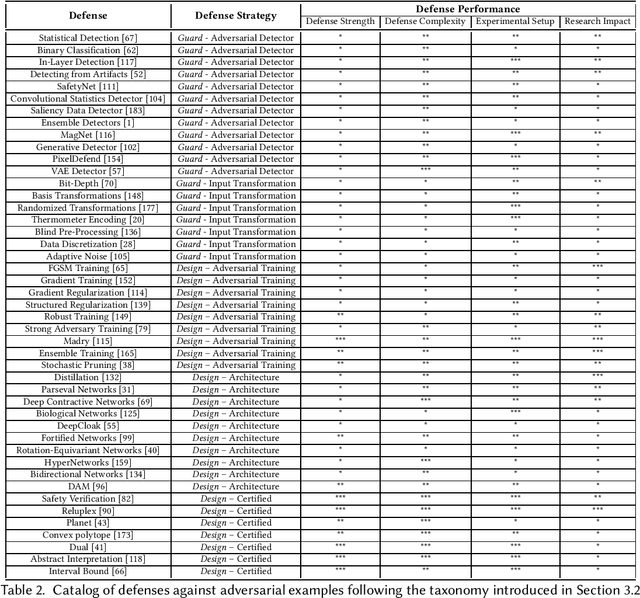

Deep neural networks are at the forefront of machine learning research. However, despite achieving impressive performance on complex tasks, they can be very sensitive: Small perturbations of inputs can be sufficient to induce incorrect behavior. Such perturbations, called adversarial examples, are intentionally designed to test the network's sensitivity to distribution drifts. Given their surprisingly small size, a wide body of literature conjectures on their existence and how this phenomenon can be mitigated. In this article we discuss the impact of adversarial examples on security, safety, and robustness of neural networks. We start by introducing the hypotheses behind their existence, the methods used to construct or protect against them, and the capacity to transfer adversarial examples between different machine learning models. Altogether, the goal is to provide a comprehensive and self-contained survey of this growing field of research.