 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploiting oddsmaker bias to improve the prediction of NFL outcomes
Oct 19, 2017



Accurately predicting the outcome of sporting events has been a goal for many groups who seek to maximize profit. What makes this challenging is that the outcome of an event can be influenced by many factors that dynamically change across time. Oddsmakers attempt to estimate these factors by using both algorithmic and subjective methods to set the spread. However, it is well-known that both human and algorithmic decision-making can be biased, so this paper explores if oddsmaker biases can be used in an exploitative manner, in order to improve the prediction of NFL game outcomes. Real-world gambling data was used to train and test different predictive models under varying assumptions. The results show that methods that leverage oddsmaker biases in an exploitative manner perform best under the conditions tested in this paper. These findings suggest that leveraging human and algorithmic decision biases in an exploitative manner may be useful for predicting the outcomes of competitive events, and could lead to increased profit for those who have financial interest in the outcomes.
Estimating the risk associated with transportation technology using multifidelity simulation
Jan 31, 2017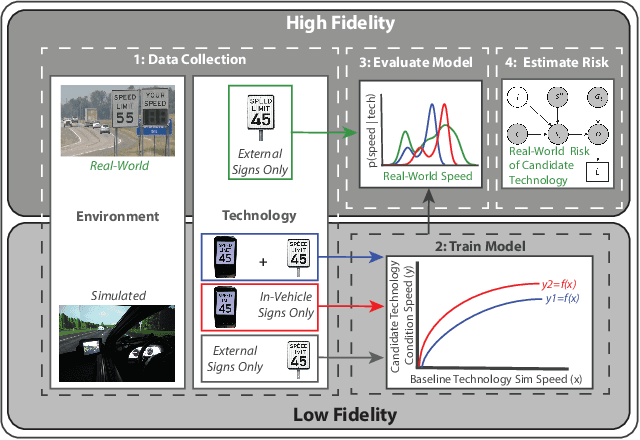

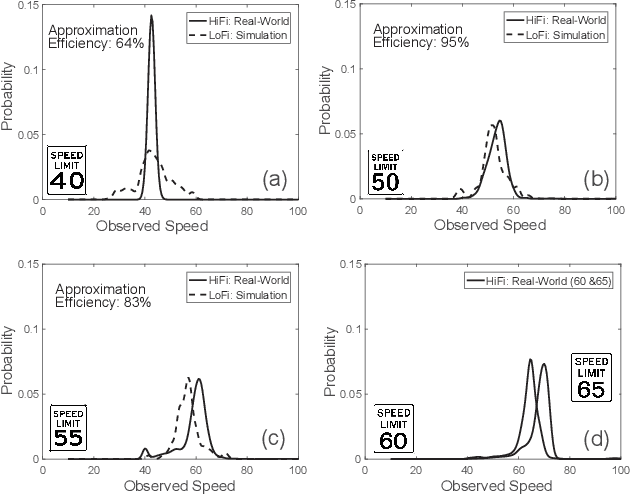
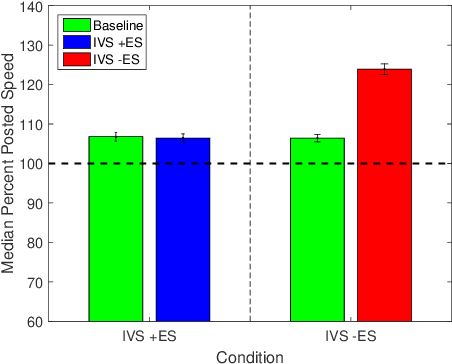
This paper provides a quantitative method for estimating the risk associated with candidate transportation technology, before it is developed and deployed. The proposed solution extends previous methods that rely exclusively on low-fidelity human-in-the-loop experimental data, or high-fidelity traffic data, by adopting a multifidelity approach that leverages data from both low- and high-fidelity sources. The multifidelity method overcomes limitations inherent to existing approaches by allowing a model to be trained inexpensively, while still assuring that its predictions generalize to the real-world. This allows for candidate technologies to be evaluated at the stage of conception, and enables a mechanism for only the safest and most effective technology to be developed and released.
Predicting the behavior of interacting humans by fusing data from multiple sources
Aug 09, 2014

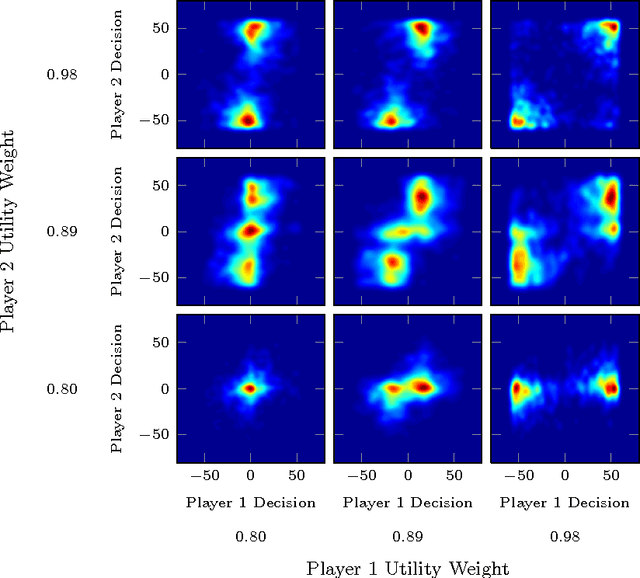

Multi-fidelity methods combine inexpensive low-fidelity simulations with costly but highfidelity simulations to produce an accurate model of a system of interest at minimal cost. They have proven useful in modeling physical systems and have been applied to engineering problems such as wing-design optimization. During human-in-the-loop experimentation, it has become increasingly common to use online platforms, like Mechanical Turk, to run low-fidelity experiments to gather human performance data in an efficient manner. One concern with these experiments is that the results obtained from the online environment generalize poorly to the actual domain of interest. To address this limitation, we extend traditional multi-fidelity approaches to allow us to combine fewer data points from high-fidelity human-in-the-loop experiments with plentiful but less accurate data from low-fidelity experiments to produce accurate models of how humans interact. We present both model-based and model-free methods, and summarize the predictive performance of each method under dierent conditions.