 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClassification of Raw MEG/EEG Data with Detach-Rocket Ensemble: An Improved ROCKET Algorithm for Multivariate Time Series Analysis
Aug 05, 2024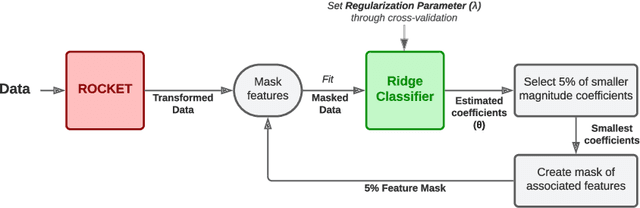

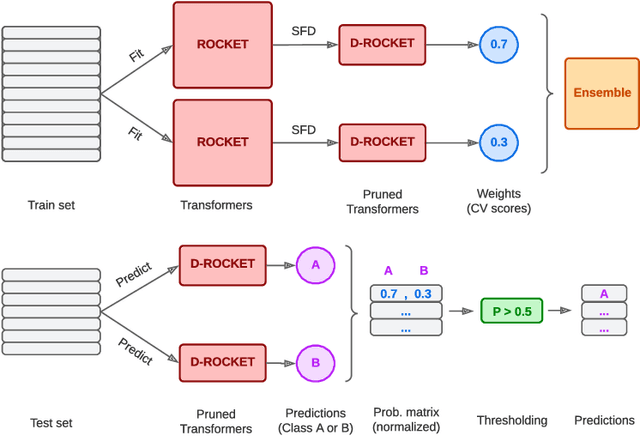
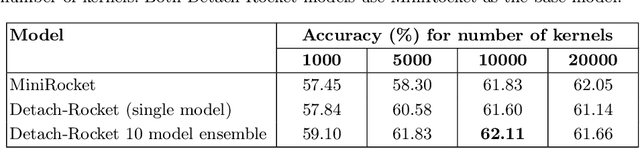
Multivariate Time Series Classification (MTSC) is a ubiquitous problem in science and engineering, particularly in neuroscience, where most data acquisition modalities involve the simultaneous time-dependent recording of brain activity in multiple brain regions. In recent years, Random Convolutional Kernel models such as ROCKET and MiniRocket have emerged as highly effective time series classification algorithms, capable of achieving state-of-the-art accuracy results with low computational load. Despite their success, these types of models face two major challenges when employed in neuroscience: 1) they struggle to deal with high-dimensional data such as EEG and MEG, and 2) they are difficult to interpret. In this work, we present a novel ROCKET-based algorithm, named Detach-Rocket Ensemble, that is specifically designed to address these two problems in MTSC. Our algorithm leverages pruning to provide an integrated estimation of channel importance, and ensembles to achieve better accuracy and provide a label probability. Using a synthetic multivariate time series classification dataset in which we control the amount of information carried by each of the channels, we first show that our algorithm is able to correctly recover the channel importance for classification. Then, using two real-world datasets, a MEG dataset and an EEG dataset, we show that Detach-Rocket Ensemble is able to provide both interpretable channel relevance and competitive classification accuracy, even when applied directly to the raw brain data, without the need for feature engineering.
Deep Learning for Time Series Classification of Parkinson's Disease Eye Tracking Data
Nov 28, 2023Eye-tracking is an accessible and non-invasive technology that provides information about a subject's motor and cognitive abilities. As such, it has proven to be a valuable resource in the study of neurodegenerative diseases such as Parkinson's disease. Saccade experiments, in particular, have proven useful in the diagnosis and staging of Parkinson's disease. However, to date, no single eye-movement biomarker has been found to conclusively differentiate patients from healthy controls. In the present work, we investigate the use of state-of-the-art deep learning algorithms to perform Parkinson's disease classification using eye-tracking data from saccade experiments. In contrast to previous work, instead of using hand-crafted features from the saccades, we use raw $\sim1.5\,s$ long fixation intervals recorded during the preparatory phase before each trial. Using these short time series as input we implement two different classification models, InceptionTime and ROCKET. We find that the models are able to learn the classification task and generalize to unseen subjects. InceptionTime achieves $78\%$ accuracy, while ROCKET achieves $88\%$ accuracy. We also employ a novel method for pruning the ROCKET model to improve interpretability and generalizability, achieving an accuracy of $96\%$. Our results suggest that fixation data has low inter-subject variability and potentially carries useful information about brain cognitive and motor conditions, making it suitable for use with machine learning in the discovery of disease-relevant biomarkers.
Detach-ROCKET: Sequential feature selection for time series classification with random convolutional kernels
Sep 25, 2023Time series classification is essential in many fields, such as medicine, finance, environmental science, and manufacturing, enabling tasks like disease diagnosis, anomaly detection, and stock price prediction. Machine learning models like Recurrent Neural Networks and InceptionTime, while successful in numerous applications, can face scalability limitations due to intensive training requirements. To address this, random convolutional kernel models such as Rocket and its derivatives have emerged, simplifying training and achieving state-of-the-art performance by utilizing a large number of randomly generated features from time series data. However, due to their random nature, most of the generated features are redundant or non-informative, adding unnecessary computational load and compromising generalization. Here, we introduce Sequential Feature Detachment (SFD) as a method to identify and prune these non-essential features. SFD uses model coefficients to estimate feature importance and, unlike previous algorithms, can handle large feature sets without the need for complex hyperparameter tuning. Testing on the UCR archive demonstrates that SFD can produce models with $10\%$ of the original features while improving $0.2\%$ the accuracy on the test set. We also present an end-to-end procedure for determining an optimal balance between the number of features and model accuracy, called Detach-ROCKET. When applied to the largest binary UCR dataset, Detach-ROCKET is capable of reduce model size by $98.9\%$ and increases test accuracy by $0.6\%$.