 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Arousal-Valence Representation from Categorical Emotion Labels of Speech
Nov 24, 2023

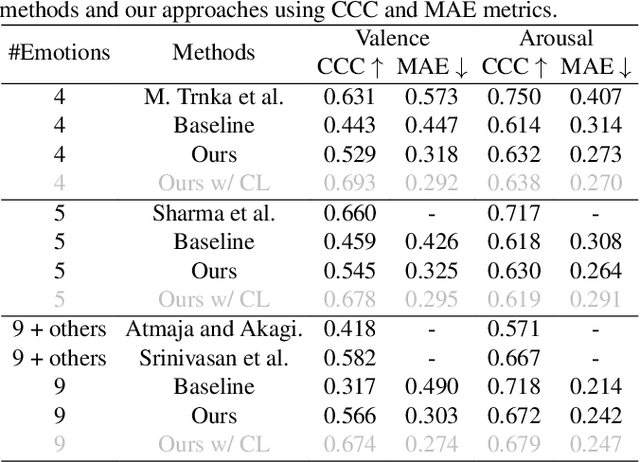

Dimensional representations of speech emotions such as the arousal-valence (AV) representation provide a continuous and fine-grained description and control than their categorical counterparts. They have wide applications in tasks such as dynamic emotion understanding and expressive text-to-speech synthesis. Existing methods that predict the dimensional emotion representation from speech cast it as a supervised regression task. These methods face data scarcity issues, as dimensional annotations are much harder to acquire than categorical labels. In this work, we propose to learn the AV representation from categorical emotion labels of speech. We start by learning a rich and emotion-relevant high-dimensional speech feature representation using self-supervised pre-training and emotion classification fine-tuning. This representation is then mapped to the 2D AV space according to psychological findings through anchored dimensionality reduction. Experiments show that our method achieves a Concordance Correlation Coefficient (CCC) performance comparable to state-of-the-art supervised regression methods on IEMOCAP without leveraging ground-truth AV annotations during training. This validates our proposed approach on AV prediction. Furthermore, visualization of AV predictions on MEAD and EmoDB datasets shows the interpretability of the learned AV representations.