 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSTaR-DRO: Stateful Tsallis Reweighting for Group-Robust Structured Prediction
Apr 09, 2026Structured prediction requires models to generate ontology-constrained labels, grounded evidence, and valid structure under ambiguity, label skew, and heterogeneous group difficulty. We present a two-part framework for controllable inference and robust fine-tuning. First, we introduce a task-agnostic prompting strategy that combines XML-based instruction structure, disambiguation rules, verification-style reasoning, schema constraints, and self-validation to address format drift, label ambiguity, evidence hallucination, and metadata-conditioned confusion in in-context structured generation. Second, we introduce STaR-DRO, a stateful robust optimization method for group heterogeneity. It combines Tsallis mirror descent with momentum-smoothed, centered group-loss signals and bounded excess-only multipliers so that only persistently hard groups above a neutral baseline are upweighted, concentrating learning where it is most needed while avoiding volatile, dense exponentiated-gradient reweighting and unnecessary loss from downweighting easier groups. We evaluate the combined framework on EPPC Miner, a benchmark for extracting hierarchical labels and evidence spans from patient-provider secure messages. Prompt engineering improves zero-shot by +15.44 average F1 across Code, Sub-code, and Span over four Llama models. Building on supervised fine-tuning, STaR-DRO further improves the hardest semantic decisions: on Llama-3.3-70B-Instruct, Code F1 rises from 79.24 to 81.47 and Sub-code F1 from 67.78 to 69.30, while preserving Span performance and reducing group-wise validation cross-entropy by up to 29.6% on the most difficult clinical categories. Because these rare and difficult groups correspond to clinically consequential communication behaviors, these gains are not merely statistical improvements: they directly strengthen communication mining reliability for patient-centered care analysis.
Yale-DM-Lab at ArchEHR-QA 2026: Deterministic Grounding and Multi-Pass Evidence Alignment for EHR Question Answering
Apr 08, 2026We describe the Yale-DM-Lab system for the ArchEHR-QA 2026 shared task. The task studies patient-authored questions about hospitalization records and contains four subtasks (ST): clinician-interpreted question reformulation, evidence sentence identification, answer generation, and evidence-answer alignment. ST1 uses a dual-model pipeline with Claude Sonnet 4 and GPT-4o to reformulate patient questions into clinician-interpreted questions. ST2-ST4 rely on Azure-hosted model ensembles (o3, GPT-5.2, GPT-5.1, and DeepSeek-R1) combined with few-shot prompting and voting strategies. Our experiments show three main findings. First, model diversity and ensemble voting consistently improve performance compared to single-model baselines. Second, the full clinician answer paragraph is provided as additional prompt context for evidence alignment. Third, results on the development set show that alignment accuracy is mainly limited by reasoning. The best scores on the development set reach 88.81 micro F1 on ST4, 65.72 macro F1 on ST2, 34.01 on ST3, and 33.05 on ST1.
Transforming Dental Diagnostics with Artificial Intelligence: Advanced Integration of ChatGPT and Large Language Models for Patient Care
Jun 07, 2024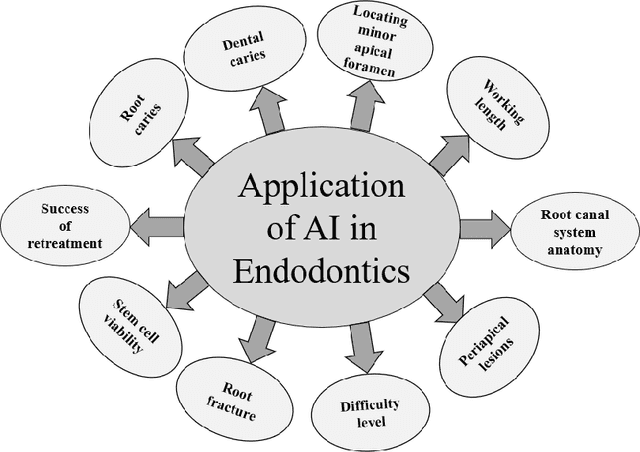
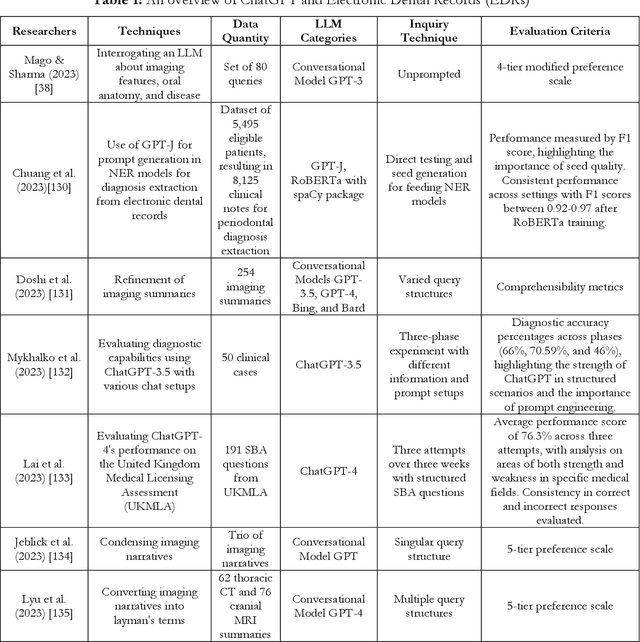
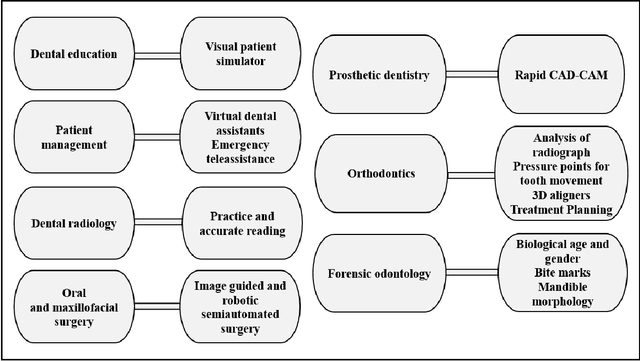
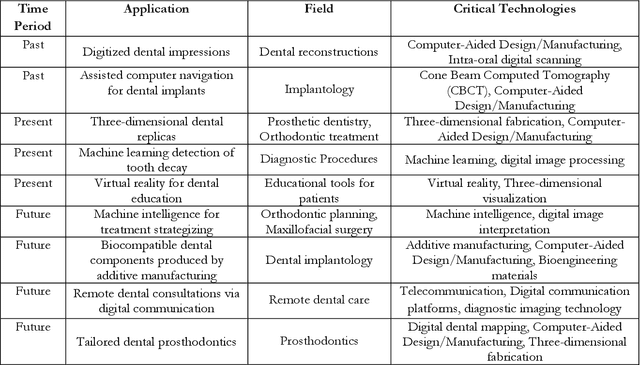
Artificial intelligence has dramatically reshaped our interaction with digital technologies, ushering in an era where advancements in AI algorithms and Large Language Models (LLMs) have natural language processing (NLP) systems like ChatGPT. This study delves into the impact of cutting-edge LLMs, notably OpenAI's ChatGPT, on medical diagnostics, with a keen focus on the dental sector. Leveraging publicly accessible datasets, these models augment the diagnostic capabilities of medical professionals, streamline communication between patients and healthcare providers, and enhance the efficiency of clinical procedures. The advent of ChatGPT-4 is poised to make substantial inroads into dental practices, especially in the realm of oral surgery. This paper sheds light on the current landscape and explores potential future research directions in the burgeoning field of LLMs, offering valuable insights for both practitioners and developers. Furthermore, it critically assesses the broad implications and challenges within various sectors, including academia and healthcare, thus mapping out an overview of AI's role in transforming dental diagnostics for enhanced patient care.
Comparative Analysis of Segment Anything Model and U-Net for Breast Tumor Detection in Ultrasound and Mammography Images
Jun 21, 2023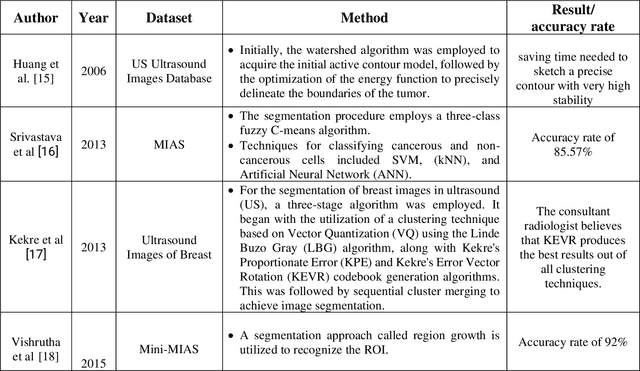

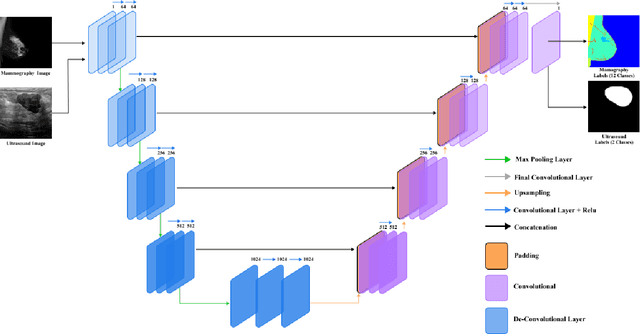

In this study, the main objective is to develop an algorithm capable of identifying and delineating tumor regions in breast ultrasound (BUS) and mammographic images. The technique employs two advanced deep learning architectures, namely U-Net and pretrained SAM, for tumor segmentation. The U-Net model is specifically designed for medical image segmentation and leverages its deep convolutional neural network framework to extract meaningful features from input images. On the other hand, the pretrained SAM architecture incorporates a mechanism to capture spatial dependencies and generate segmentation results. Evaluation is conducted on a diverse dataset containing annotated tumor regions in BUS and mammographic images, covering both benign and malignant tumors. This dataset enables a comprehensive assessment of the algorithm's performance across different tumor types. Results demonstrate that the U-Net model outperforms the pretrained SAM architecture in accurately identifying and segmenting tumor regions in both BUS and mammographic images. The U-Net exhibits superior performance in challenging cases involving irregular shapes, indistinct boundaries, and high tumor heterogeneity. In contrast, the pretrained SAM architecture exhibits limitations in accurately identifying tumor areas, particularly for malignant tumors and objects with weak boundaries or complex shapes. These findings highlight the importance of selecting appropriate deep learning architectures tailored for medical image segmentation. The U-Net model showcases its potential as a robust and accurate tool for tumor detection, while the pretrained SAM architecture suggests the need for further improvements to enhance segmentation performance.