 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplainable artificial intelligence toward usable and trustworthy computer-aided early diagnosis of multiple sclerosis from Optical Coherence Tomography
Feb 13, 2023



Background: Several studies indicate that the anterior visual pathway provides information about the dynamics of axonal degeneration in Multiple Sclerosis (MS). Current research in the field is focused on the quest for the most discriminative features among patients and controls and the development of machine learning models that yield computer-aided solutions widely usable in clinical practice. However, most studies are conducted with small samples and the models are used as black boxes. Clinicians should not trust machine learning decisions unless they come with comprehensive and easily understandable explanations. Materials and methods: A total of 216 eyes from 111 healthy controls and 100 eyes from 59 patients with relapsing-remitting MS were enrolled. The feature set was obtained from the thickness of the ganglion cell layer (GCL) and the retinal nerve fiber layer (RNFL). Measurements were acquired by the novel Posterior Pole protocol from Spectralis Optical Coherence Tomography (OCT) device. We compared two black-box methods (gradient boosting and random forests) with a glass-box method (explainable boosting machine). Explainability was studied using SHAP for the black-box methods and the scores of the glass-box method. Results: The best-performing models were obtained for the GCL layer. Explainability pointed out to the temporal location of the GCL layer that is usually broken or thinning in MS and the relationship between low thickness values and high probability of MS, which is coherent with clinical knowledge. Conclusions: The insights on how to use explainability shown in this work represent a first important step toward a trustworthy computer-aided solution for the diagnosis of MS with OCT.
LDDMM meets GANs: Generative Adversarial Networks for diffeomorphic registration
Nov 24, 2021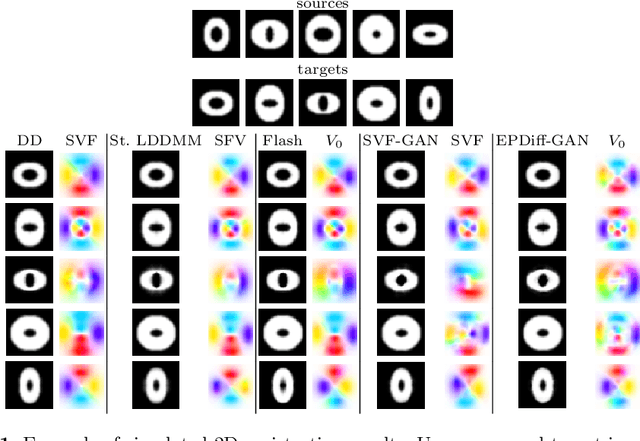
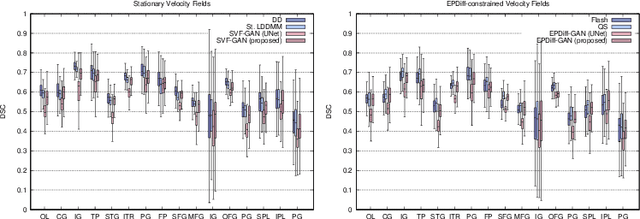
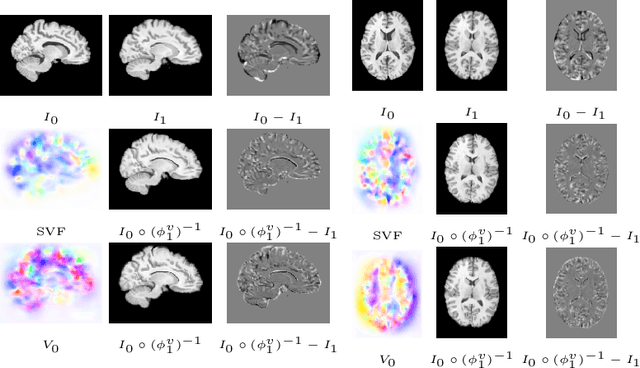
The purpose of this work is to contribute to the state of the art of deep-learning methods for diffeomorphic registration. We propose an adversarial learning LDDMM method for pairs of 3D mono-modal images based on Generative Adversarial Networks. The method is inspired by the recent literature for deformable image registration with adversarial learning. We combine the best performing generative, discriminative, and adversarial ingredients from the state of the art within the LDDMM paradigm. We have successfully implemented two models with the stationary and the EPDiff-constrained non-stationary parameterizations of diffeomorphisms. Our unsupervised and data-hungry approach has shown a competitive performance with respect to a benchmark supervised and rich-data approach. In addition, our method has shown similar results to model-based methods with a computational time under one second.
Resource-bounded Dimension in Computational Learning Theory
Jan 14, 2011This paper focuses on the relation between computational learning theory and resource-bounded dimension. We intend to establish close connections between the learnability/nonlearnability of a concept class and its corresponding size in terms of effective dimension, which will allow the use of powerful dimension techniques in computational learning and viceversa, the import of learning results into complexity via dimension. Firstly, we obtain a tight result on the dimension of online mistake-bound learnable classes. Secondly, in relation with PAC learning, we show that the polynomial-space dimension of PAC learnable classes of concepts is zero. This provides a hypothesis on effective dimension that implies the inherent unpredictability of concept classes (the classes that verify this property are classes not efficiently PAC learnable using any hypothesis). Thirdly, in relation to space dimension of classes that are learnable by membership query algorithms, the main result proves that polynomial-space dimension of concept classes learnable by a membership-query algorithm is zero.