 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe RNA Newton Polytope and Learnability of Energy Parameters
Jan 08, 2013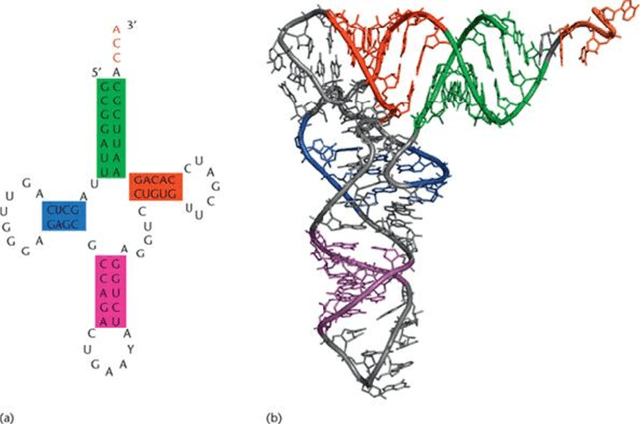


Despite nearly two scores of research on RNA secondary structure and RNA-RNA interaction prediction, the accuracy of the state-of-the-art algorithms are still far from satisfactory. Researchers have proposed increasingly complex energy models and improved parameter estimation methods in anticipation of endowing their methods with enough power to solve the problem. The output has disappointingly been only modest improvements, not matching the expectations. Even recent massively featured machine learning approaches were not able to break the barrier. In this paper, we introduce the notion of learnability of the parameters of an energy model as a measure of its inherent capability. We say that the parameters of an energy model are learnable iff there exists at least one set of such parameters that renders every known RNA structure to date the minimum free energy structure. We derive a necessary condition for the learnability and give a dynamic programming algorithm to assess it. Our algorithm computes the convex hull of the feature vectors of all feasible structures in the ensemble of a given input sequence. Interestingly, that convex hull coincides with the Newton polytope of the partition function as a polynomial in energy parameters. We demonstrated the application of our theory to a simple energy model consisting of a weighted count of A-U and C-G base pairs. Our results show that this simple energy model satisfies the necessary condition for less than one third of the input unpseudoknotted sequence-structure pairs chosen from the RNA STRAND v2.0 database. For another one third, the necessary condition is barely violated, which suggests that augmenting this simple energy model with more features such as the Turner loops may solve the problem. The necessary condition is severely violated for 8%, which provides a small set of hard cases that require further investigation.
An Efficient Algorithm for Upper Bound on the Partition Function of Nucleic Acids
Jan 08, 2013
It has been shown that minimum free energy structure for RNAs and RNA-RNA interaction is often incorrect due to inaccuracies in the energy parameters and inherent limitations of the energy model. In contrast, ensemble based quantities such as melting temperature and equilibrium concentrations can be more reliably predicted. Even structure prediction by sampling from the ensemble and clustering those structures by Sfold [7] has proven to be more reliable than minimum free energy structure prediction. The main obstacle for ensemble based approaches is the computational complexity of the partition function and base pairing probabilities. For instance, the space complexity of the partition function for RNA-RNA interaction is $O(n^4)$ and the time complexity is $O(n^6)$ which are prohibitively large [4,12]. Our goal in this paper is to give a fast algorithm, based on sparse folding, to calculate an upper bound on the partition function. Our work is based on the recent algorithm of Hazan and Jaakkola [10]. The space complexity of our algorithm is the same as that of sparse folding algorithms, and the time complexity of our algorithm is $O(MFE(n)\ell)$ for single RNA and $O(MFE(m, n)\ell)$ for RNA-RNA interaction in practice, in which $MFE$ is the running time of sparse folding and $\ell \leq n$ ($\ell \leq n + m$) is a sequence dependent parameter.