 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLibrarian-in-the-Loop: A Natural Language Processing Paradigm for Detecting Informal Mentions of Research Data in Academic Literature
Mar 10, 2022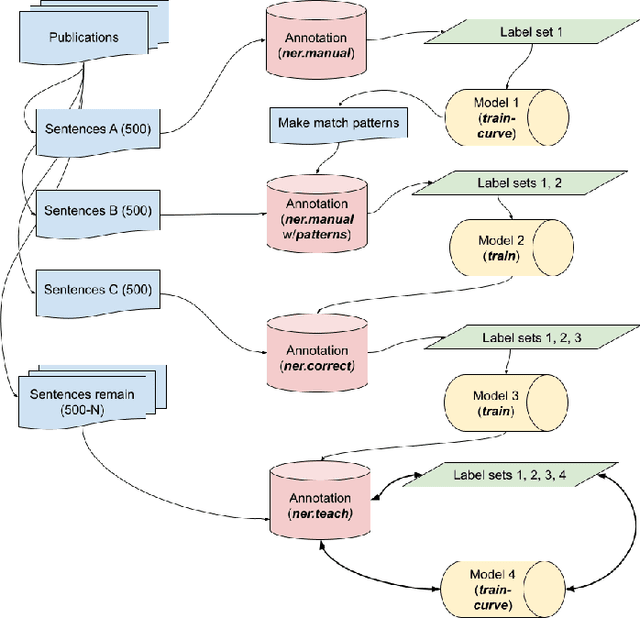
Data citations provide a foundation for studying research data impact. Collecting and managing data citations is a new frontier in archival science and scholarly communication. However, the discovery and curation of research data citations is labor intensive. Data citations that reference unique identifiers (i.e. DOIs) are readily findable; however, informal mentions made to research data are more challenging to infer. We propose a natural language processing (NLP) paradigm to support the human task of identifying informal mentions made to research datasets. The work of discovering informal data mentions is currently performed by librarians and their staff in the Inter-university Consortium for Political and Social Research (ICPSR), a large social science data archive that maintains a large bibliography of data-related literature. The NLP model is bootstrapped from data citations actively collected by librarians at ICPSR. The model combines pattern matching with multiple iterations of human annotations to learn additional rules for detecting informal data mentions. These examples are then used to train an NLP pipeline. The librarian-in-the-loop paradigm is centered in the data work performed by ICPSR librarians, supporting broader efforts to build a more comprehensive bibliography of data-related literature that reflects the scholarly communities of research data users.