 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterpretable Bangla Sarcasm Detection using BERT and Explainable AI
Mar 22, 2023



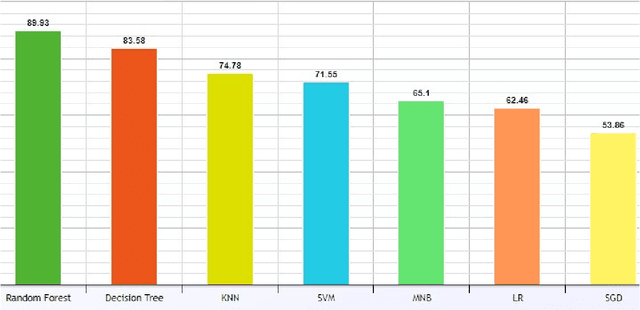
A positive phrase or a sentence with an underlying negative motive is usually defined as sarcasm that is widely used in today's social media platforms such as Facebook, Twitter, Reddit, etc. In recent times active users in social media platforms are increasing dramatically which raises the need for an automated NLP-based system that can be utilized in various tasks such as determining market demand, sentiment analysis, threat detection, etc. However, since sarcasm usually implies the opposite meaning and its detection is frequently a challenging issue, data meaning extraction through an NLP-based model becomes more complicated. As a result, there has been a lot of study on sarcasm detection in English over the past several years, and there's been a noticeable improvement and yet sarcasm detection in the Bangla language's state remains the same. In this article, we present a BERT-based system that can achieve 99.60\% while the utilized traditional machine learning algorithms are only capable of achieving 89.93\%. Additionally, we have employed Local Interpretable Model-Agnostic Explanations that introduce explainability to our system. Moreover, we have utilized a newly collected bangla sarcasm dataset, BanglaSarc that was constructed specifically for the evaluation of this study. This dataset consists of fresh records of sarcastic and non-sarcastic comments, the majority of which are acquired from Facebook and YouTube comment sections.
BanglaSarc: A Dataset for Sarcasm Detection
Sep 27, 2022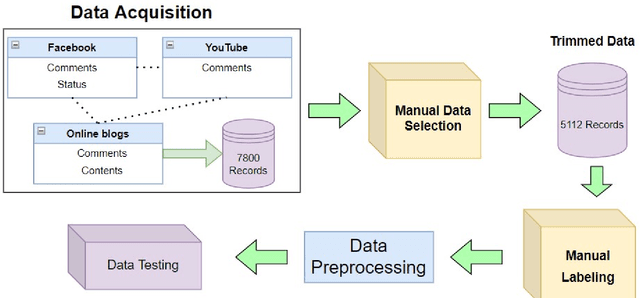
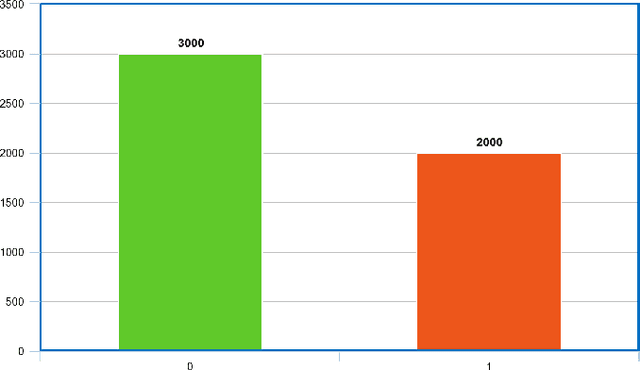
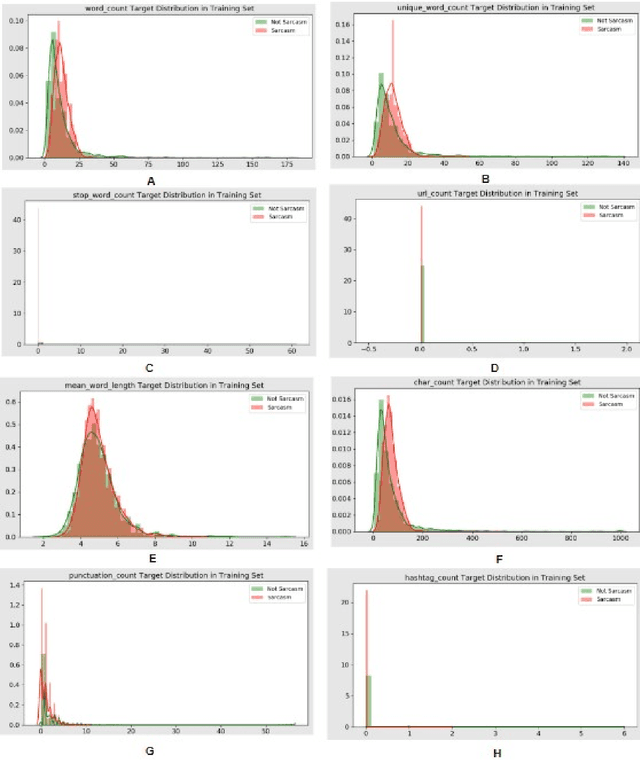
Being one of the most widely spoken language in the world, the use of Bangla has been increasing in the world of social media as well. Sarcasm is a positive statement or remark with an underlying negative motivation that is extensively employed in today's social media platforms. There has been a significant improvement in sarcasm detection in English over the previous many years, however the situation regarding Bangla sarcasm detection remains unchanged. As a result, it is still difficult to identify sarcasm in bangla, and a lack of high-quality data is a major contributing factor. This article proposes BanglaSarc, a dataset constructed specifically for bangla textual data sarcasm detection. This dataset contains of 5112 comments/status and contents collected from various online social platforms such as Facebook, YouTube, along with a few online blogs. Due to the limited amount of data collection of categorized comments in Bengali, this dataset will aid in the of study identifying sarcasm, recognizing people's emotion, detecting various types of Bengali expressions, and other domains. The dataset is publicly available at https://www.kaggle.com/datasets/sakibapon/banglasarc.