 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBanglaSarc: A Dataset for Sarcasm Detection
Sep 27, 2022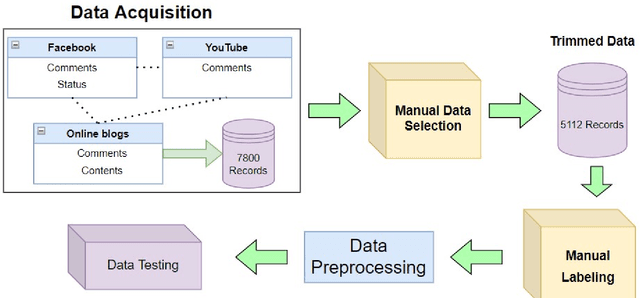
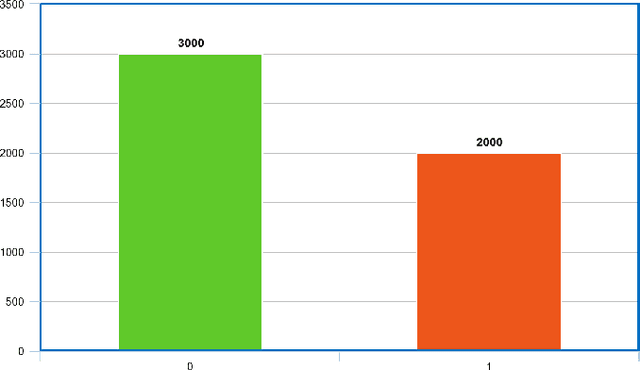
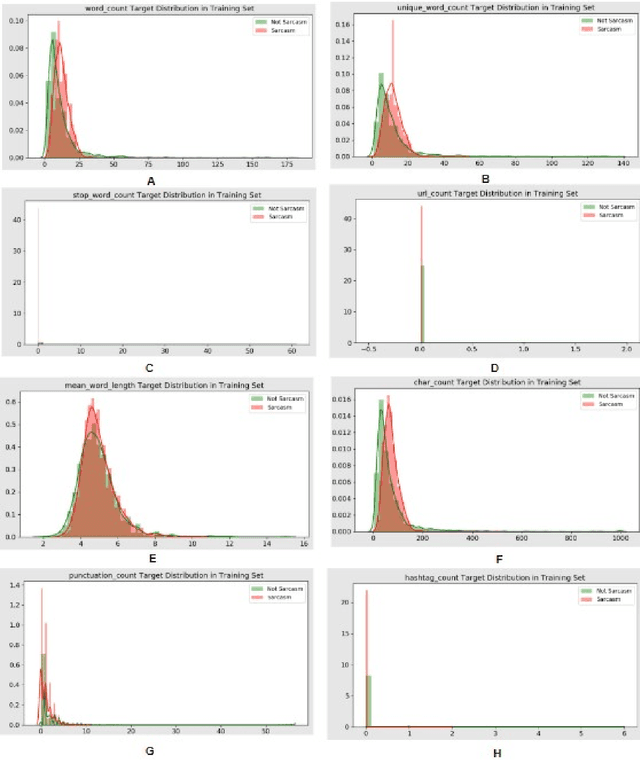
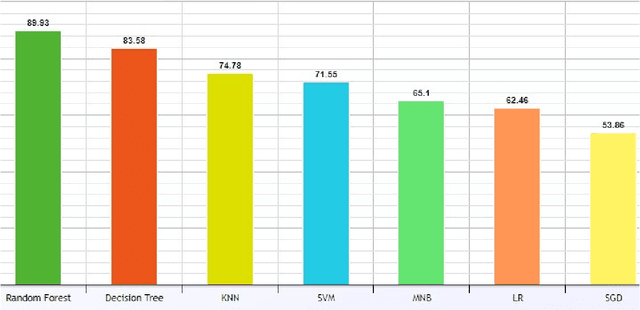
Being one of the most widely spoken language in the world, the use of Bangla has been increasing in the world of social media as well. Sarcasm is a positive statement or remark with an underlying negative motivation that is extensively employed in today's social media platforms. There has been a significant improvement in sarcasm detection in English over the previous many years, however the situation regarding Bangla sarcasm detection remains unchanged. As a result, it is still difficult to identify sarcasm in bangla, and a lack of high-quality data is a major contributing factor. This article proposes BanglaSarc, a dataset constructed specifically for bangla textual data sarcasm detection. This dataset contains of 5112 comments/status and contents collected from various online social platforms such as Facebook, YouTube, along with a few online blogs. Due to the limited amount of data collection of categorized comments in Bengali, this dataset will aid in the of study identifying sarcasm, recognizing people's emotion, detecting various types of Bengali expressions, and other domains. The dataset is publicly available at https://www.kaggle.com/datasets/sakibapon/banglasarc.