 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePersonalized Speech-driven Expressive 3D Facial Animation Synthesis with Style Control
Oct 25, 2023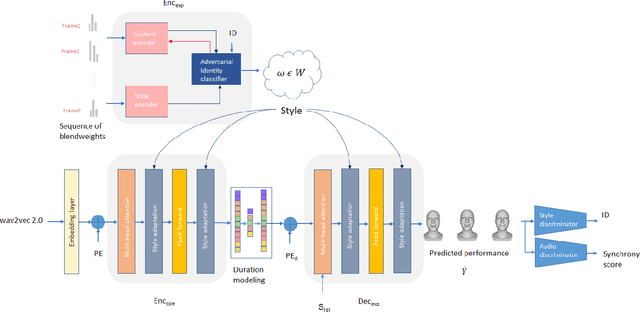
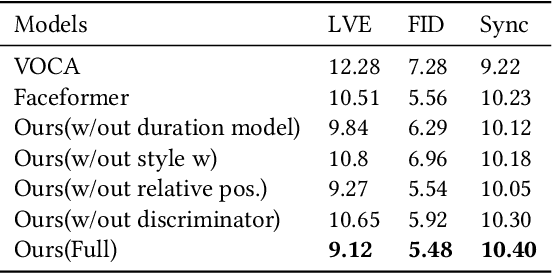
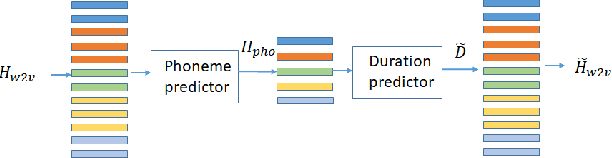
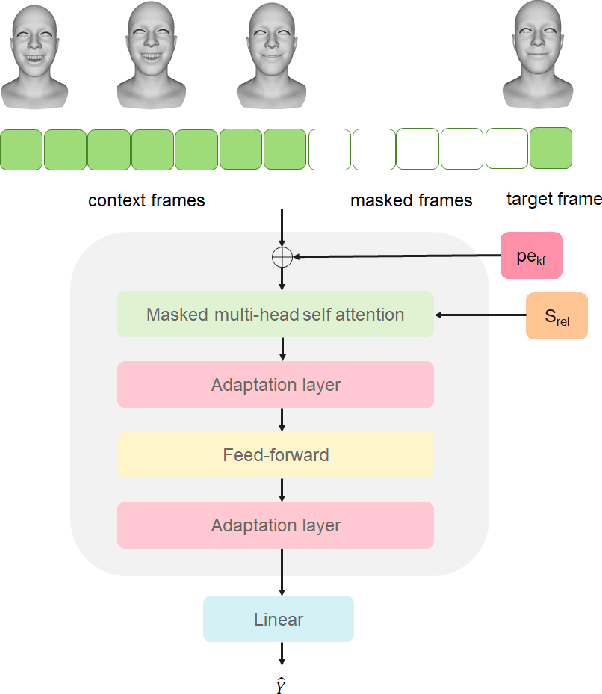
Different people have different facial expressions while speaking emotionally. A realistic facial animation system should consider such identity-specific speaking styles and facial idiosyncrasies to achieve high-degree of naturalness and plausibility. Existing approaches to personalized speech-driven 3D facial animation either use one-hot identity labels or rely-on person specific models which limit their scalability. We present a personalized speech-driven expressive 3D facial animation synthesis framework that models identity specific facial motion as latent representations (called as styles), and synthesizes novel animations given a speech input with the target style for various emotion categories. Our framework is trained in an end-to-end fashion and has a non-autoregressive encoder-decoder architecture with three main components: expression encoder, speech encoder and expression decoder. Since, expressive facial motion includes both identity-specific style and speech-related content information; expression encoder first disentangles facial motion sequences into style and content representations, respectively. Then, both of the speech encoder and the expression decoders input the extracted style information to update transformer layer weights during training phase. Our speech encoder also extracts speech phoneme label and duration information to achieve better synchrony within the non-autoregressive synthesis mechanism more effectively. Through detailed experiments, we demonstrate that our approach produces temporally coherent facial expressions from input speech while preserving the speaking styles of the target identities.
BEAT: A Large-Scale Semantic and Emotional Multi-Modal Dataset for Conversational Gestures Synthesis
Mar 18, 2022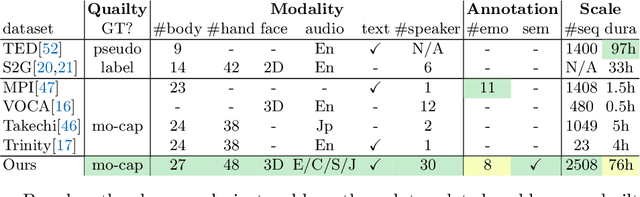
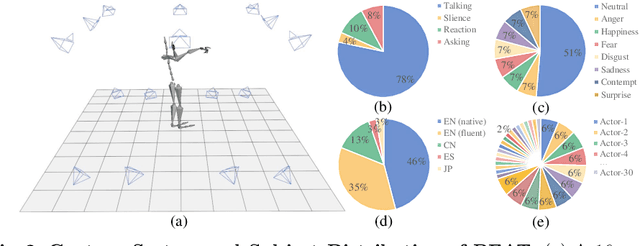

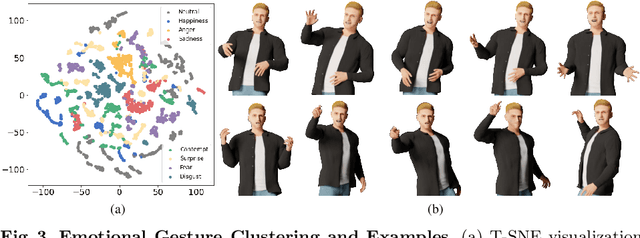
Achieving realistic, vivid, and human-like synthesized conversational gestures conditioned on multi-modal data is still an unsolved problem, due to the lack of available datasets, models and standard evaluation metrics. To address this, we build Body-Expression-Audio-Text dataset, BEAT, which has i) 76 hours, high-quality, multi-modal data captured from 30 speakers talking with eight different emotions and in four different languages, ii) 32 millions frame-level emotion and semantic relevance annotations.Our statistical analysis on BEAT demonstrates the correlation of conversational gestures with facial expressions, emotions, and semantics, in addition to the known correlation with audio, text, and speaker identity. Qualitative and quantitative experiments demonstrate metrics' validness, ground truth data quality, and baseline's state-of-the-art performance. To the best of our knowledge, BEAT is the largest motion capture dataset for investigating the human gestures, which may contribute to a number of different research fields including controllable gesture synthesis, cross-modality analysis, emotional gesture recognition. The data, code and model will be released for research.