 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCausality-aware counterfactual confounding adjustment as an alternative to linear residualization in anticausal prediction tasks based on linear learners
Nov 09, 2020

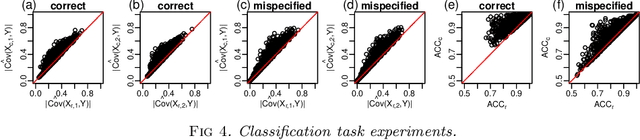
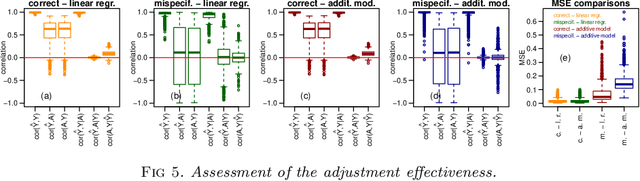
Linear residualization is a common practice for confounding adjustment in machine learning (ML) applications. Recently, causality-aware predictive modeling has been proposed as an alternative causality-inspired approach for adjusting for confounders. The basic idea is to simulate counterfactual data that is free from the spurious associations generated by the observed confounders. In this paper, we compare the linear residualization approach against the causality-aware confounding adjustment in anticausal prediction tasks, and show that the causality-aware approach tends to (asymptotically) outperform the residualization adjustment in terms of predictive performance in linear learners. Importantly, our results still holds even when the true model is not linear. We illustrate our results in both regression and classification tasks, where we compared the causality-aware and residualization approaches using mean squared errors and classification accuracy in synthetic data experiments where the linear regression model is mispecified, as well as, when the linear model is correctly specified. Furthermore, we illustrate how the causality-aware approach is more stable than residualization with respect to dataset shifts in the joint distribution of the confounders and outcome variables.
Stable predictions for health related anticausal prediction tasks affected by selection biases: the need to deconfound the test set features
Nov 09, 2020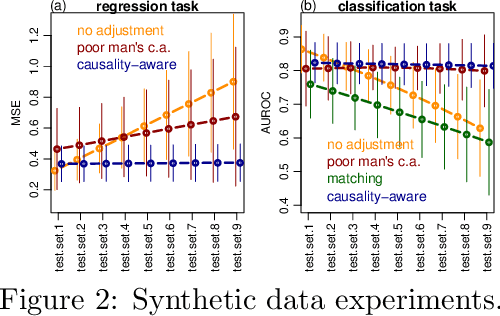
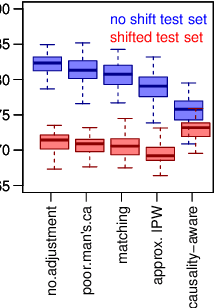
In health related machine learning applications, the training data often corresponds to a non-representative sample from the target populations where the learners will be deployed. In anticausal prediction tasks, selection biases often make the associations between confounders and the outcome variable unstable across different target environments. As a consequence, the predictions from confounded learners are often unstable, and might fail to generalize in shifted test environments. Stable prediction approaches aim to solve this problem by producing predictions that are stable across unknown test environments. These approaches, however, are sometimes applied to the training data alone with the hope that training an unconfounded model will be enough to generate stable predictions in shifted test sets. Here, we show that this is insufficient, and that improved stability can be achieved by deconfounding the test set features as well. We illustrate these observations using both synthetic data and real world data from a mobile health study.
Counterfactual confounding adjustment for feature representations learned by deep models: with an application to image classification tasks
Apr 23, 2020



Causal modeling has been recognized as a potential solution to many challenging problems in machine learning (ML). While counterfactual thinking has been leveraged in ML tasks that aim to predict the consequences of actions/interventions, it has not yet been applied to more traditional/static supervised learning tasks, such as the prediction of labels in image classification tasks. Here, we propose a counterfactual approach to remove/reduce the influence of confounders from the predictions generated a deep neural network (DNN). The idea is to remove confounding from the feature representations learned by DNNs in anticausal prediction tasks. By training an accurate DNN using softmax activation at the classification layer, and then adopting the representation learned by the last layer prior to the output layer as our features, we have that, by construction, the learned features will fit well a (multi-class) logistic regression model, and will be linearly associated with the labels. Then, in order to generate classifiers that are free from the influence of the observed confounders we: (i) use linear models to regress each learned feature on the labels and on the confounders and estimate the respective regression coefficients and model residuals; (ii) generate new counterfactual features by adding back to the estimated residuals to a linear predictor which no longer includes the confounder variables; and (iii) train and evaluate a logistic classifier using the counterfactual features as inputs. We validate the proposed methodology using colored versions of the MNIST and fashion-MNIST datasets, and show how the approach can effectively combat confounding and improve generalization in the context of dataset shift. Finally, we also describe how to use conditional independence tests to evaluate if the counterfactual approach has effectively removed the confounder signals from the predictions.
Detecting Learning vs Memorization in Deep Neural Networks using Shared Structure Validation Sets
Feb 21, 2018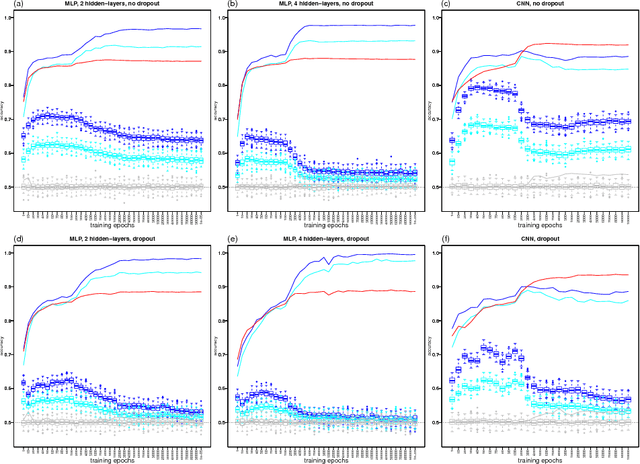


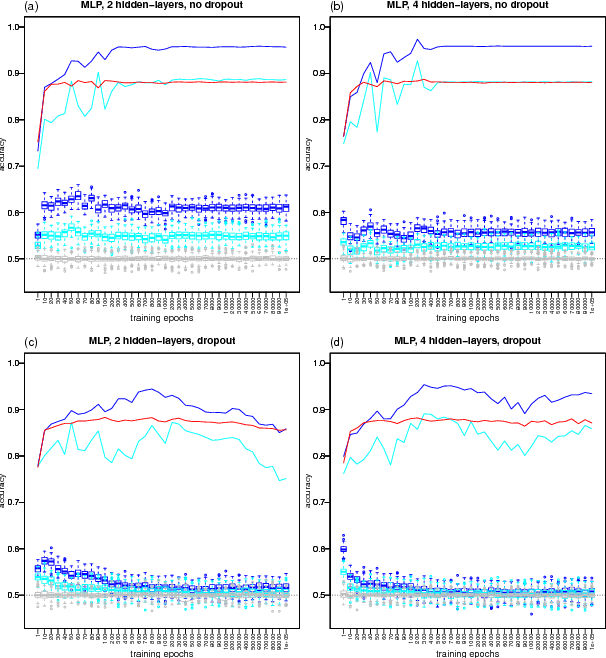
The roles played by learning and memorization represent an important topic in deep learning research. Recent work on this subject has shown that the optimization behavior of DNNs trained on shuffled labels is qualitatively different from DNNs trained with real labels. Here, we propose a novel permutation approach that can differentiate memorization from learning in deep neural networks (DNNs) trained as usual (i.e., using the real labels to guide the learning, rather than shuffled labels). The evaluation of weather the DNN has learned and/or memorized, happens in a separate step where we compare the predictive performance of a shallow classifier trained with the features learned by the DNN, against multiple instances of the same classifier, trained on the same input, but using shuffled labels as outputs. By evaluating these shallow classifiers in validation sets that share structure with the training set, we are able to tell apart learning from memorization. Application of our permutation approach to multi-layer perceptrons and convolutional neural networks trained on image data corroborated many findings from other groups. Most importantly, our illustrations also uncovered interesting dynamic patterns about how DNNs memorize over increasing numbers of training epochs, and support the surprising result that DNNs are still able to learn, rather than only memorize, when trained with pure Gaussian noise as input.