 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStable predictions for health related anticausal prediction tasks affected by selection biases: the need to deconfound the test set features
Nov 09, 2020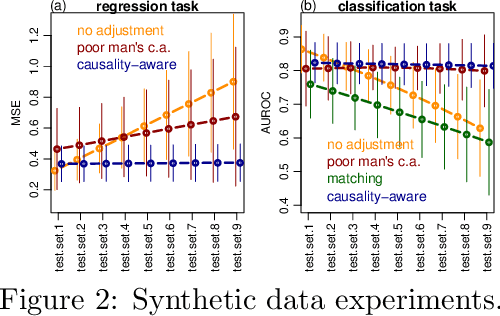
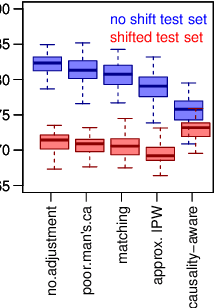
In health related machine learning applications, the training data often corresponds to a non-representative sample from the target populations where the learners will be deployed. In anticausal prediction tasks, selection biases often make the associations between confounders and the outcome variable unstable across different target environments. As a consequence, the predictions from confounded learners are often unstable, and might fail to generalize in shifted test environments. Stable prediction approaches aim to solve this problem by producing predictions that are stable across unknown test environments. These approaches, however, are sometimes applied to the training data alone with the hope that training an unconfounded model will be enough to generate stable predictions in shifted test sets. Here, we show that this is insufficient, and that improved stability can be achieved by deconfounding the test set features as well. We illustrate these observations using both synthetic data and real world data from a mobile health study.