 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTechnical Report on Data Integration and Preparation
Mar 02, 2021

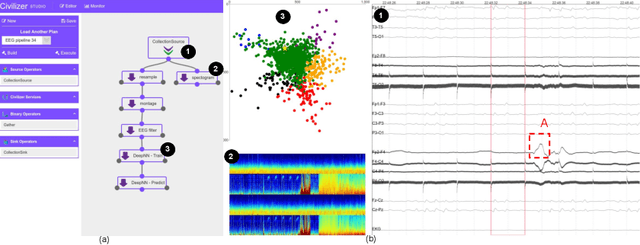
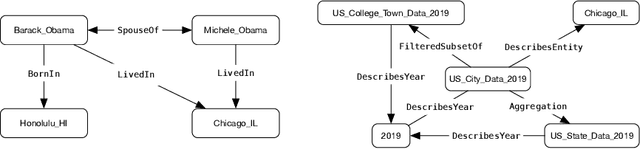
AI application developers typically begin with a dataset of interest and a vision of the end analytic or insight they wish to gain from the data at hand. Although these are two very important components of an AI workflow, one often spends the first few weeks (sometimes months) in the phase we refer to as data conditioning. This step typically includes tasks such as figuring out how to prepare data for analytics, dealing with inconsistencies in the dataset, and determining which algorithm (or set of algorithms) will be best suited for the application. Larger, faster, and messier datasets such as those from Internet of Things sensors, medical devices or autonomous vehicles only amplify these issues. These challenges, often referred to as the three Vs (volume, velocity, variety) of Big Data, require low-level tools for data management, preparation and integration. In most applications, data can come from structured and/or unstructured sources and often includes inconsistencies, formatting differences, and a lack of ground-truth labels. In this report, we highlight a number of tools that can be used to simplify data integration and preparation steps. Specifically, we focus on data integration tools and techniques, a deep dive into an exemplar data integration tool, and a deep-dive in the evolving field of knowledge graphs. Finally, we provide readers with a list of practical steps and considerations that they can use to simplify the data integration challenge. The goal of this report is to provide readers with a view of state-of-the-art as well as practical tips that can be used by data creators that make data integration more seamless.