 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReal-Time Optimal Guidance and Control for Interplanetary Transfers Using Deep Networks
Feb 20, 2020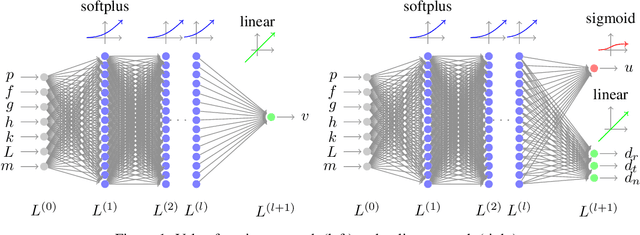



We consider the Earth-Venus mass-optimal interplanetary transfer of a low-thrust spacecraft and show how the optimal guidance can be represented by deep networks in a large portion of the state space and to a high degree of accuracy. Imitation (supervised) learning of optimal examples is used as a network training paradigm. The resulting models are suitable for an on-board, real-time, implementation of the optimal guidance and control system of the spacecraft and are called G&CNETs. A new general methodology called Backward Generation of Optimal Examples is introduced and shown to be able to efficiently create all the optimal state action pairs necessary to train G&CNETs without solving optimal control problems. With respect to previous works, we are able to produce datasets containing a few orders of magnitude more optimal trajectories and obtain network performances compatible with real missions requirements. Several schemes able to train representations of either the optimal policy (thrust profile) or the value function (optimal mass) are proposed and tested. We find that both policy learning and value function learning successfully and accurately learn the optimal thrust and that a spacecraft employing the learned thrust is able to reach the target conditions orbit spending only 2 permil more propellant than in the corresponding mathematically optimal transfer. Moreover, the optimal propellant mass can be predicted (in case of value function learning) within an error well within 1%. All G&CNETs produced are tested during simulations of interplanetary transfers with respect to their ability to reach the target conditions optimally starting from nominal and off-nominal conditions.
Interplanetary Transfers via Deep Representations of the Optimal Policy and/or of the Value Function
Apr 18, 2019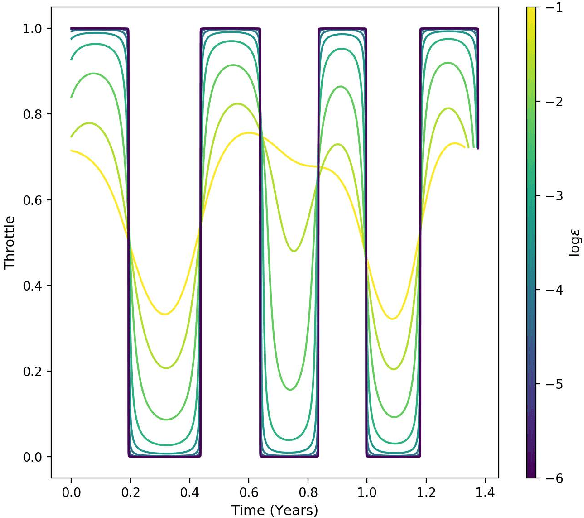
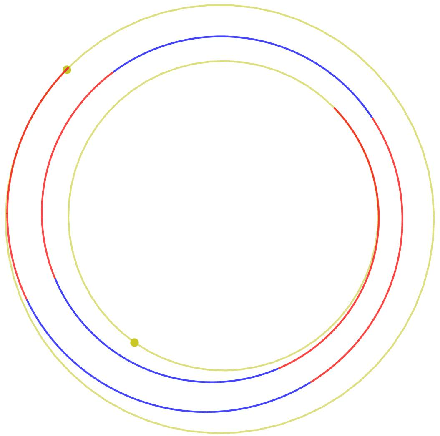
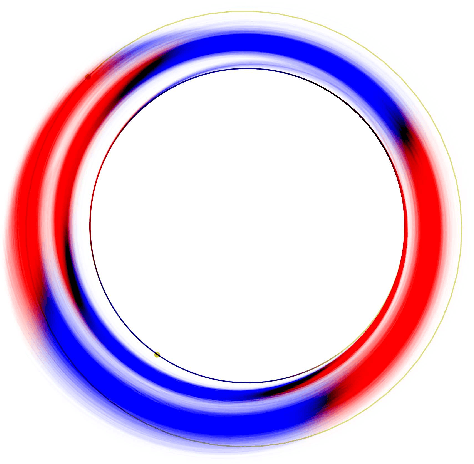
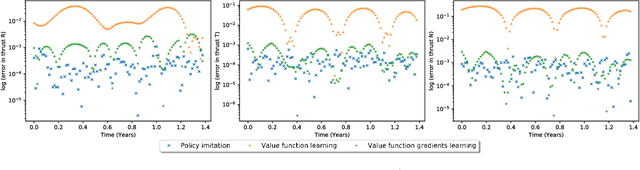
A number of applications to interplanetary trajectories have been recently proposed based on deep networks. These approaches often rely on the availability of a large number of optimal trajectories to learn from. In this paper we introduce a new method to quickly create millions of optimal spacecraft trajectories from a single nominal trajectory. Apart from the generation of the nominal trajectory, no additional optimal control problems need to be solved as all the trajectories, by construction, satisfy Pontryagin's minimum principle and the relevant transversality conditions. We then consider deep feed forward neural networks and benchmark three learning methods on the created dataset: policy imitation, value function learning and value function gradient learning. Our results are shown for the case of the interplanetary trajectory optimization problem of reaching Venus orbit, with the nominal trajectory starting from the Earth. We find that both policy imitation and value function gradient learning are able to learn the optimal state feedback, while in the case of value function learning the optimal policy is not captured, only the final value of the optimal propellant mass is.