 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBayesian Decision Trees Inspired from Evolutionary Algorithms
May 30, 2023


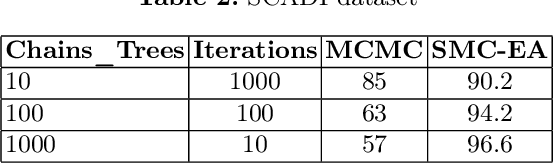
Bayesian Decision Trees (DTs) are generally considered a more advanced and accurate model than a regular Decision Tree (DT) because they can handle complex and uncertain data. Existing work on Bayesian DTs uses Markov Chain Monte Carlo (MCMC) with an accept-reject mechanism and sample using naive proposals to proceed to the next iteration, which can be slow because of the burn-in time needed. We can reduce the burn-in period by proposing a more sophisticated way of sampling or by designing a different numerical Bayesian approach. In this paper, we propose a replacement of the MCMC with an inherently parallel algorithm, the Sequential Monte Carlo (SMC), and a more effective sampling strategy inspired by the Evolutionary Algorithms (EA). Experiments show that SMC combined with the EA can produce more accurate results compared to MCMC in 100 times fewer iterations.
Parallel Approaches to Accelerate Bayesian Decision Trees
Jan 22, 2023
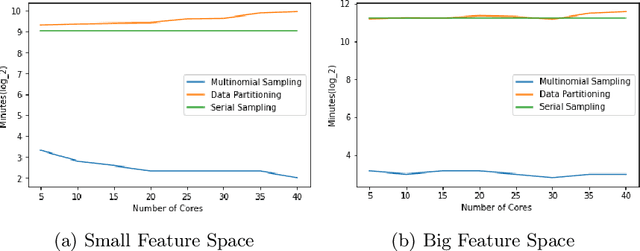
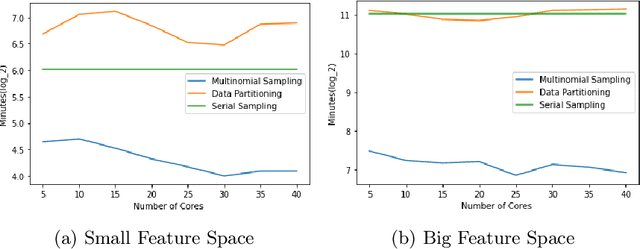
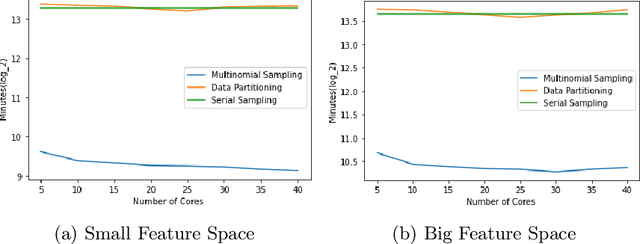
Markov Chain Monte Carlo (MCMC) is a well-established family of algorithms primarily used in Bayesian statistics to sample from a target distribution when direct sampling is challenging. Existing work on Bayesian decision trees uses MCMC. Unfortunately, this can be slow, especially when considering large volumes of data. It is hard to parallelise the accept-reject component of the MCMC. None-the-less, we propose two methods for exploiting parallelism in the MCMC: in the first, we replace the MCMC with another numerical Bayesian approach, the Sequential Monte Carlo (SMC) sampler, which has the appealing property that it is an inherently parallel algorithm; in the second, we consider data partitioning. Both methods use multi-core processing with a HighPerformance Computing (HPC) resource. We test the two methods in various study settings to determine which method is the most beneficial for each test case. Experiments show that data partitioning has limited utility in the settings we consider and that the use of the SMC sampler can improve run-time (compared to the sequential implementation) by up to a factor of 343.
Single MCMC Chain Parallelisation on Decision Trees
Jul 26, 2022
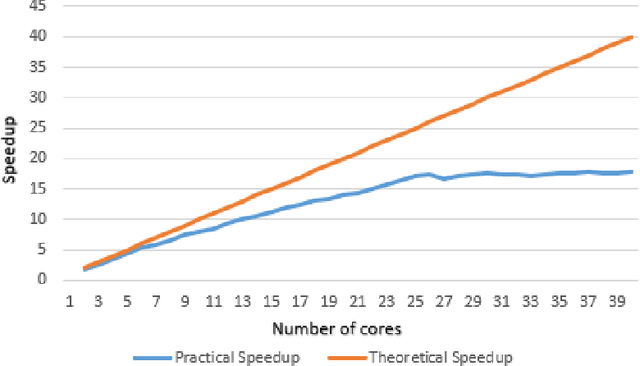


Decision trees are highly famous in machine learning and usually acquire state-of-the-art performance. Despite that, well-known variants like CART, ID3, random forest, and boosted trees miss a probabilistic version that encodes prior assumptions about tree structures and shares statistical strength between node parameters. Existing work on Bayesian decision trees depend on Markov Chain Monte Carlo (MCMC), which can be computationally slow, especially on high dimensional data and expensive proposals. In this study, we propose a method to parallelise a single MCMC decision tree chain on an average laptop or personal computer that enables us to reduce its run-time through multi-core processing while the results are statistically identical to conventional sequential implementation. We also calculate the theoretical and practical reduction in run time, which can be obtained utilising our method on multi-processor architectures. Experiments showed that we could achieve 18 times faster running time provided that the serial and the parallel implementation are statistically identical.