 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBoosting Generative Image Modeling via Joint Image-Feature Synthesis
Apr 22, 2025Latent diffusion models (LDMs) dominate high-quality image generation, yet integrating representation learning with generative modeling remains a challenge. We introduce a novel generative image modeling framework that seamlessly bridges this gap by leveraging a diffusion model to jointly model low-level image latents (from a variational autoencoder) and high-level semantic features (from a pretrained self-supervised encoder like DINO). Our latent-semantic diffusion approach learns to generate coherent image-feature pairs from pure noise, significantly enhancing both generative quality and training efficiency, all while requiring only minimal modifications to standard Diffusion Transformer architectures. By eliminating the need for complex distillation objectives, our unified design simplifies training and unlocks a powerful new inference strategy: Representation Guidance, which leverages learned semantics to steer and refine image generation. Evaluated in both conditional and unconditional settings, our method delivers substantial improvements in image quality and training convergence speed, establishing a new direction for representation-aware generative modeling.
Technical Report for the 5th CLVision Challenge at CVPR: Addressing the Class-Incremental with Repetition using Unlabeled Data -- 4th Place Solution
Mar 19, 2025This paper outlines our approach to the 5th CLVision challenge at CVPR, which addresses the Class-Incremental with Repetition (CIR) scenario. In contrast to traditional class incremental learning, this novel setting introduces unique challenges and research opportunities, particularly through the integration of unlabeled data into the training process. In the CIR scenario, encountered classes may reappear in later learning experiences, and each experience may involve only a subset of the overall class distribution. Additionally, the unlabeled data provided during training may include instances of unseen classes, or irrelevant classes which should be ignored. Our approach focuses on retaining previously learned knowledge by utilizing knowledge distillation and pseudo-labeling techniques. The key characteristic of our method is the exploitation of unlabeled data during training, in order to maintain optimal performance on instances of previously encountered categories and reduce the detrimental effects of catastrophic forgetting. Our method achieves an average accuracy of 16.68\% during the pre-selection phase and 21.19% during the final evaluation phase, outperforming the baseline accuracy of 9.39%. We provide the implementation code at https://github.com/panagiotamoraiti/continual-learning-challenge-2024 .
Advancing Semantic Future Prediction through Multimodal Visual Sequence Transformers
Jan 14, 2025



Semantic future prediction is important for autonomous systems navigating dynamic environments. This paper introduces FUTURIST, a method for multimodal future semantic prediction that uses a unified and efficient visual sequence transformer architecture. Our approach incorporates a multimodal masked visual modeling objective and a novel masking mechanism designed for multimodal training. This allows the model to effectively integrate visible information from various modalities, improving prediction accuracy. Additionally, we propose a VAE-free hierarchical tokenization process, which reduces computational complexity, streamlines the training pipeline, and enables end-to-end training with high-resolution, multimodal inputs. We validate FUTURIST on the Cityscapes dataset, demonstrating state-of-the-art performance in future semantic segmentation for both short- and mid-term forecasting. We provide the implementation code at https://github.com/Sta8is/FUTURIST .
DINO-Foresight Looking into the Future with DINO
Dec 16, 2024



Predicting future dynamics is crucial for applications like autonomous driving and robotics, where understanding the environment is key. Existing pixel-level methods are computationally expensive and often focus on irrelevant details. To address these challenges, we introduce $\texttt{DINO-Foresight}$, a novel framework that operates in the semantic feature space of pretrained Vision Foundation Models (VFMs). Our approach trains a masked feature transformer in a self-supervised manner to predict the evolution of VFM features over time. By forecasting these features, we can apply off-the-shelf, task-specific heads for various scene understanding tasks. In this framework, VFM features are treated as a latent space, to which different heads attach to perform specific tasks for future-frame analysis. Extensive experiments show that our framework outperforms existing methods, demonstrating its robustness and scalability. Additionally, we highlight how intermediate transformer representations in $\texttt{DINO-Foresight}$ improve downstream task performance, offering a promising path for the self-supervised enhancement of VFM features. We provide the implementation code at https://github.com/Sta8is/DINO-Foresight .
Comparison Analysis of Traditional Machine Learning and Deep Learning Techniques for Data and Image Classification
Apr 11, 2022
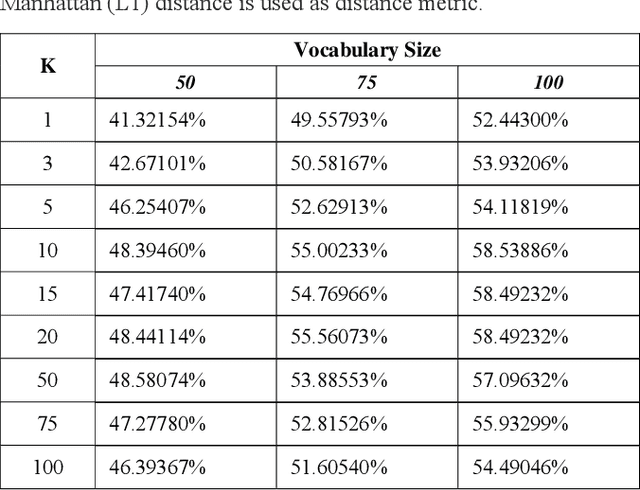


The purpose of the study is to analyse and compare the most common machine learning and deep learning techniques used for computer vision 2D object classification tasks. Firstly, we will present the theoretical background of the Bag of Visual words model and Deep Convolutional Neural Networks (DCNN). Secondly, we will implement a Bag of Visual Words model, the VGG16 CNN Architecture. Thirdly, we will present our custom and novice DCNN in which we test the aforementioned implementations on a modified version of the Belgium Traffic Sign dataset. Our results showcase the effects of hyperparameters on traditional machine learning and the advantage in terms of accuracy of DCNNs compared to classical machine learning methods. As our tests indicate, our proposed solution can achieve similar - and in some cases better - results than existing DCNNs architectures. Finally, the technical merit of this article lies in the presented computationally simpler DCNN architecture, which we believe can pave the way towards using more efficient architectures for basic tasks.