 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComparison Analysis of Traditional Machine Learning and Deep Learning Techniques for Data and Image Classification
Apr 11, 2022
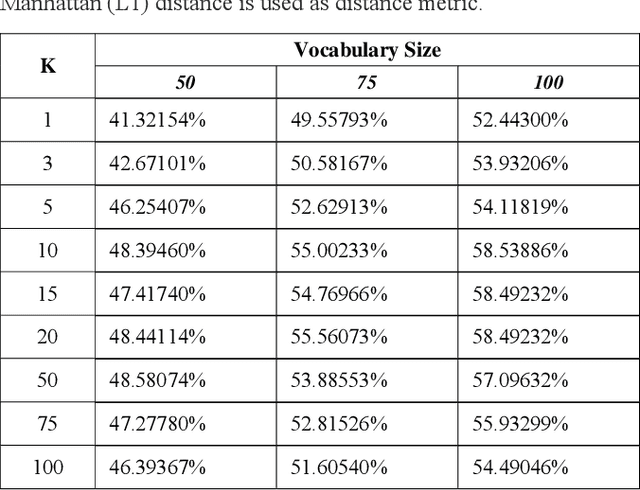


The purpose of the study is to analyse and compare the most common machine learning and deep learning techniques used for computer vision 2D object classification tasks. Firstly, we will present the theoretical background of the Bag of Visual words model and Deep Convolutional Neural Networks (DCNN). Secondly, we will implement a Bag of Visual Words model, the VGG16 CNN Architecture. Thirdly, we will present our custom and novice DCNN in which we test the aforementioned implementations on a modified version of the Belgium Traffic Sign dataset. Our results showcase the effects of hyperparameters on traditional machine learning and the advantage in terms of accuracy of DCNNs compared to classical machine learning methods. As our tests indicate, our proposed solution can achieve similar - and in some cases better - results than existing DCNNs architectures. Finally, the technical merit of this article lies in the presented computationally simpler DCNN architecture, which we believe can pave the way towards using more efficient architectures for basic tasks.