 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeconstructing word embedding algorithms
Nov 12, 2020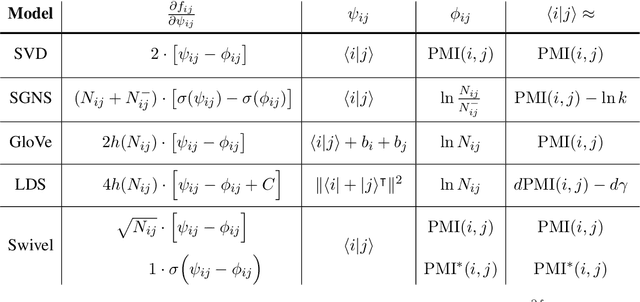
Word embeddings are reliable feature representations of words used to obtain high quality results for various NLP applications. Uncontextualized word embeddings are used in many NLP tasks today, especially in resource-limited settings where high memory capacity and GPUs are not available. Given the historical success of word embeddings in NLP, we propose a retrospective on some of the most well-known word embedding algorithms. In this work, we deconstruct Word2vec, GloVe, and others, into a common form, unveiling some of the common conditions that seem to be required for making performant word embeddings. We believe that the theoretical findings in this paper can provide a basis for more informed development of future models.
Deconstructing and reconstructing word embedding algorithms
Nov 29, 2019



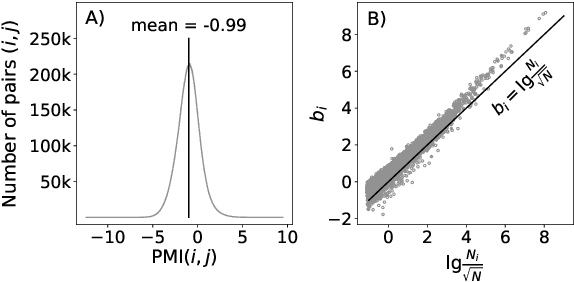
Uncontextualized word embeddings are reliable feature representations of words used to obtain high quality results for various NLP applications. Given the historical success of word embeddings in NLP, we propose a retrospective on some of the most well-known word embedding algorithms. In this work, we deconstruct Word2vec, GloVe, and others, into a common form, unveiling some of the necessary and sufficient conditions required for making performant word embeddings. We find that each algorithm: (1) fits vector-covector dot products to approximate pointwise mutual information (PMI); and, (2) modulates the loss gradient to balance weak and strong signals. We demonstrate that these two algorithmic features are sufficient conditions to construct a novel word embedding algorithm, Hilbert-MLE. We find that its embeddings obtain equivalent or better performance against other algorithms across 17 intrinsic and extrinsic datasets.
Assessing Partisan Traits of News Text Attributions
Jan 25, 2019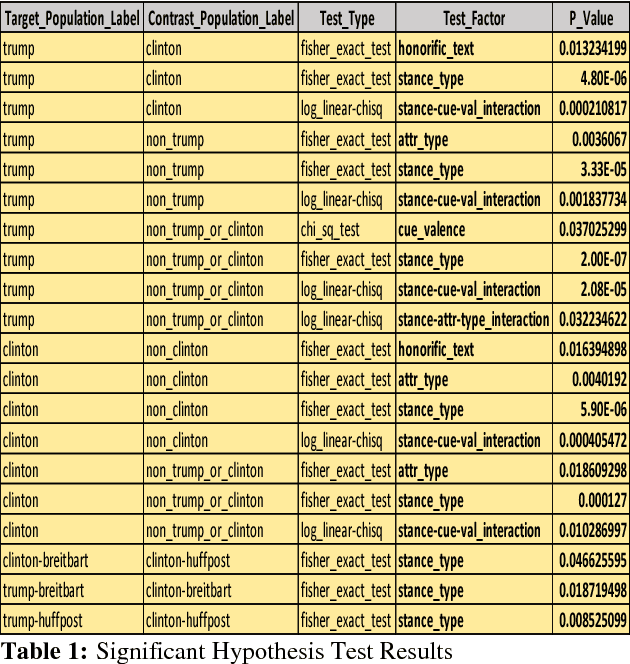
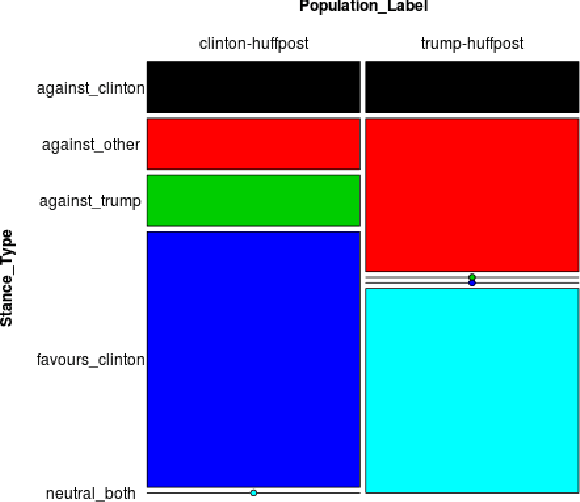
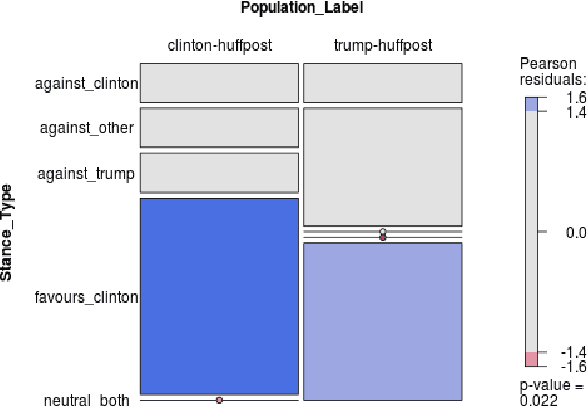
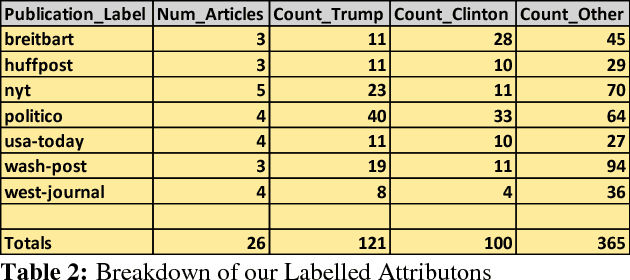
On the topic of journalistic integrity, the current state of accurate, impartial news reporting has garnered much debate in context to the 2016 US Presidential Election. In pursuit of computational evaluation of news text, the statements (attributions) ascribed by media outlets to sources provide a common category of evidence on which to operate. In this paper, we develop an approach to compare partisan traits of news text attributions and apply it to characterize differences in statements ascribed to candidate, Hilary Clinton, and incumbent President, Donald Trump. In doing so, we present a model trained on over 600 in-house annotated attributions to identify each candidate with accuracy > 88%. Finally, we discuss insights from its performance for future research.