 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnriching Abusive Language Detection with Community Context
Jun 16, 2022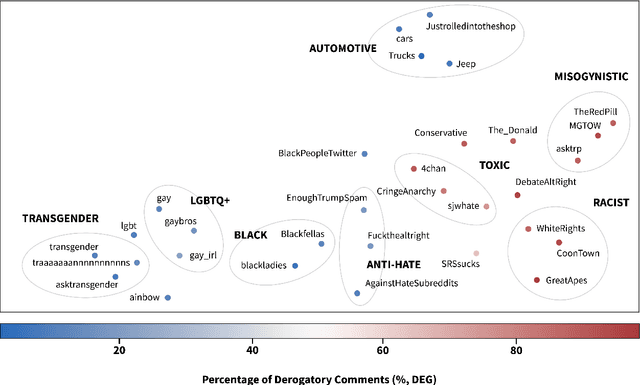



Uses of pejorative expressions can be benign or actively empowering. When models for abuse detection misclassify these expressions as derogatory, they inadvertently censor productive conversations held by marginalized groups. One way to engage with non-dominant perspectives is to add context around conversations. Previous research has leveraged user- and thread-level features, but it often neglects the spaces within which productive conversations take place. Our paper highlights how community context can improve classification outcomes in abusive language detection. We make two main contributions to this end. First, we demonstrate that online communities cluster by the nature of their support towards victims of abuse. Second, we establish how community context improves accuracy and reduces the false positive rates of state-of-the-art abusive language classifiers. These findings suggest a promising direction for context-aware models in abusive language research.
Legends: Folklore on Reddit
Jul 01, 2020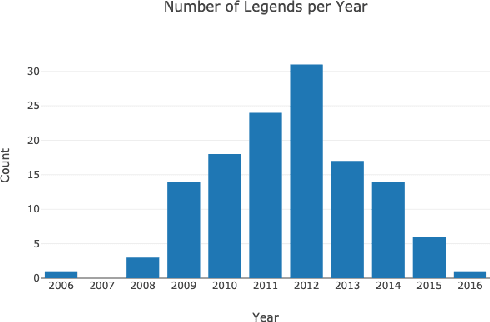
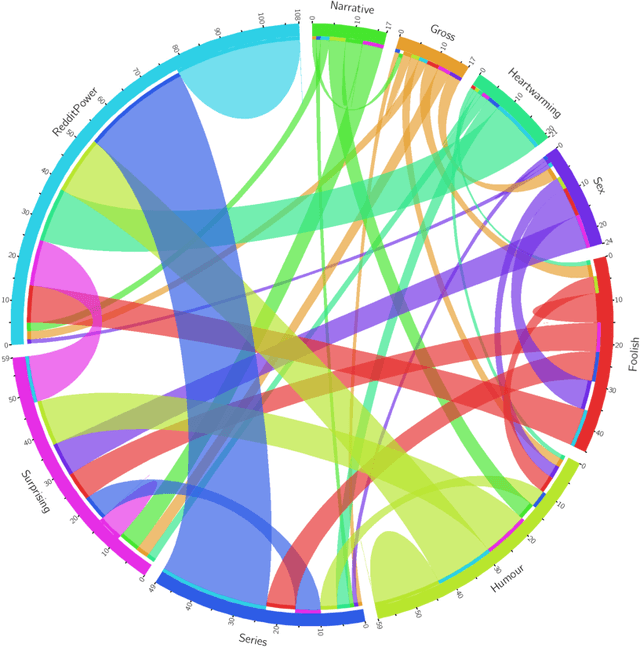
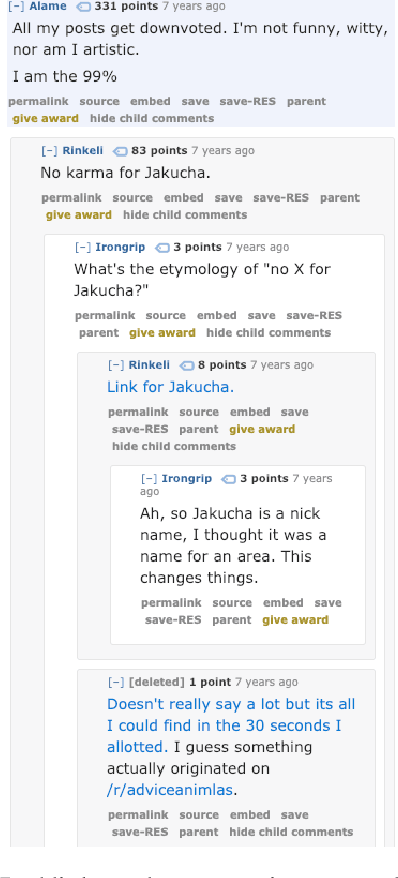
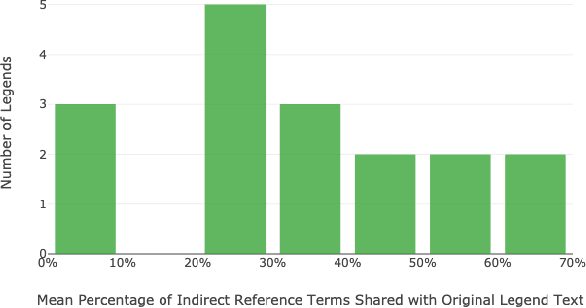
In this paper we introduce Reddit legends, a collection of venerated old posts that have become famous on Reddit. To establish the utility of Reddit legends for both computational science/HCI and folkloristics, we investigate two main questions: (1) whether they can be considered folklore, i.e. if they have consistent form, cultural significance, and undergo spontaneous transmission, and (2) whether they can be studied in a systematic manner. Through several subtasks, including the creation of a typology, an analysis of references to Reddit legends, and an examination of some of the textual characteristics of referencing behaviour, we show that Reddit legends can indeed be considered as folklore and that they are amendable to systematic text-based approaches. We discuss how these results will enable future analyses of folklore on Reddit, including tracking subreddit-wide and individual-user behaviour, and the relationship of this behaviour to other cultural markers.
Assessing Partisan Traits of News Text Attributions
Jan 25, 2019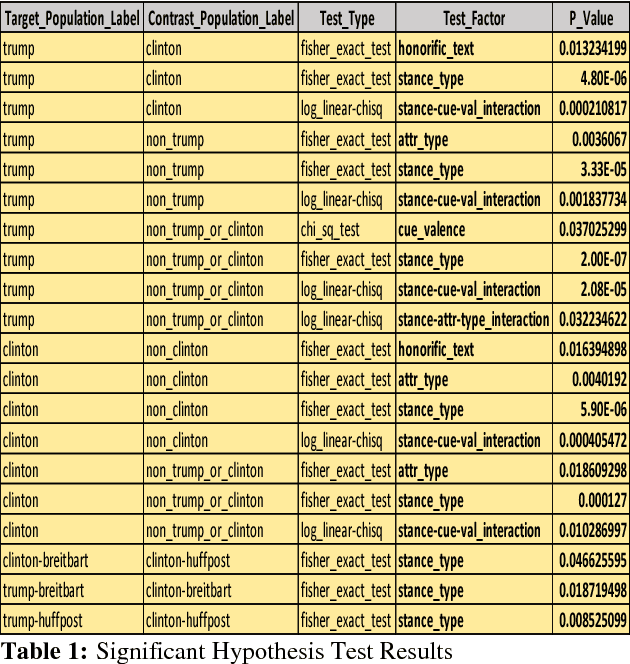
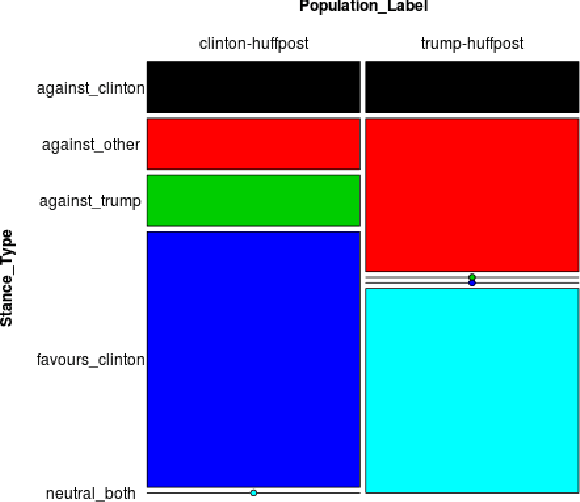
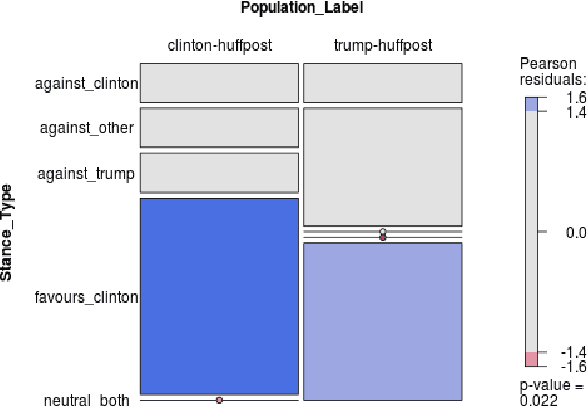
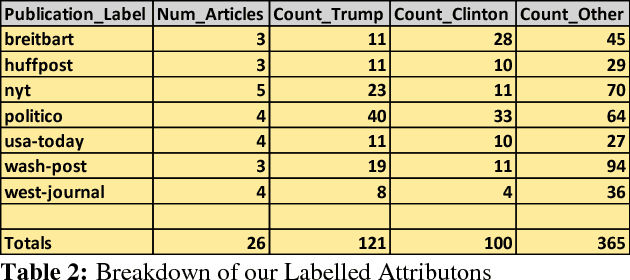
On the topic of journalistic integrity, the current state of accurate, impartial news reporting has garnered much debate in context to the 2016 US Presidential Election. In pursuit of computational evaluation of news text, the statements (attributions) ascribed by media outlets to sources provide a common category of evidence on which to operate. In this paper, we develop an approach to compare partisan traits of news text attributions and apply it to characterize differences in statements ascribed to candidate, Hilary Clinton, and incumbent President, Donald Trump. In doing so, we present a model trained on over 600 in-house annotated attributions to identify each candidate with accuracy > 88%. Finally, we discuss insights from its performance for future research.
A Web of Hate: Tackling Hateful Speech in Online Social Spaces
Sep 28, 2017



Online social platforms are beset with hateful speech - content that expresses hatred for a person or group of people. Such content can frighten, intimidate, or silence platform users, and some of it can inspire other users to commit violence. Despite widespread recognition of the problems posed by such content, reliable solutions even for detecting hateful speech are lacking. In the present work, we establish why keyword-based methods are insufficient for detection. We then propose an approach to detecting hateful speech that uses content produced by self-identifying hateful communities as training data. Our approach bypasses the expensive annotation process often required to train keyword systems and performs well across several established platforms, making substantial improvements over current state-of-the-art approaches.