 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge Language Model-driven Multi-Agent Simulation for News Diffusion Under Different Network Structures
Oct 16, 2024The proliferation of fake news in the digital age has raised critical concerns, particularly regarding its impact on societal trust and democratic processes. Diverging from conventional agent-based simulation approaches, this work introduces an innovative approach by employing a large language model (LLM)-driven multi-agent simulation to replicate complex interactions within information ecosystems. We investigate key factors that facilitate news propagation, such as agent personalities and network structures, while also evaluating strategies to combat misinformation. Through simulations across varying network structures, we demonstrate the potential of LLM-based agents in modeling the dynamics of misinformation spread, validating the influence of agent traits on the diffusion process. Our findings emphasize the advantages of LLM-based simulations over traditional techniques, as they uncover underlying causes of information spread -- such as agents promoting discussions -- beyond the predefined rules typically employed in existing agent-based models. Additionally, we evaluate three countermeasure strategies, discovering that brute-force blocking influential agents in the network or announcing news accuracy can effectively mitigate misinformation. However, their effectiveness is influenced by the network structure, highlighting the importance of considering network structure in the development of future misinformation countermeasures.
Large Language Model Agent for Fake News Detection
Apr 30, 2024



In the current digital era, the rapid spread of misinformation on online platforms presents significant challenges to societal well-being, public trust, and democratic processes, influencing critical decision making and public opinion. To address these challenges, there is a growing need for automated fake news detection mechanisms. Pre-trained large language models (LLMs) have demonstrated exceptional capabilities across various natural language processing (NLP) tasks, prompting exploration into their potential for verifying news claims. Instead of employing LLMs in a non-agentic way, where LLMs generate responses based on direct prompts in a single shot, our work introduces FactAgent, an agentic approach of utilizing LLMs for fake news detection. FactAgent enables LLMs to emulate human expert behavior in verifying news claims without any model training, following a structured workflow. This workflow breaks down the complex task of news veracity checking into multiple sub-steps, where LLMs complete simple tasks using their internal knowledge or external tools. At the final step of the workflow, LLMs integrate all findings throughout the workflow to determine the news claim's veracity. Compared to manual human verification, FactAgent offers enhanced efficiency. Experimental studies demonstrate the effectiveness of FactAgent in verifying claims without the need for any training process. Moreover, FactAgent provides transparent explanations at each step of the workflow and during final decision-making, offering insights into the reasoning process of fake news detection for end users. FactAgent is highly adaptable, allowing for straightforward updates to its tools that LLMs can leverage within the workflow, as well as updates to the workflow itself using domain knowledge. This adaptability enables FactAgent's application to news verification across various domains.
A Preliminary Study of ChatGPT on News Recommendation: Personalization, Provider Fairness, Fake News
Jun 19, 2023Online news platforms commonly employ personalized news recommendation methods to assist users in discovering interesting articles, and many previous works have utilized language model techniques to capture user interests and understand news content. With the emergence of large language models like GPT-3 and T-5, a new recommendation paradigm has emerged, leveraging pre-trained language models for making recommendations. ChatGPT, with its user-friendly interface and growing popularity, has become a prominent choice for text-based tasks. Considering the growing reliance on ChatGPT for language tasks, the importance of news recommendation in addressing social issues, and the trend of using language models in recommendations, this study conducts an initial investigation of ChatGPT's performance in news recommendations, focusing on three perspectives: personalized news recommendation, news provider fairness, and fake news detection. ChatGPT has the limitation that its output is sensitive to the input phrasing. We therefore aim to explore the constraints present in the generated responses of ChatGPT for each perspective. Additionally, we investigate whether specific prompt formats can alleviate these constraints or if these limitations require further attention from researchers in the future. We also surpass fixed evaluations by developing a webpage to monitor ChatGPT's performance on weekly basis on the tasks and prompts we investigated. Our aim is to contribute to and encourage more researchers to engage in the study of enhancing news recommendation performance through the utilization of large language models such as ChatGPT.
PBNR: Prompt-based News Recommender System
Apr 16, 2023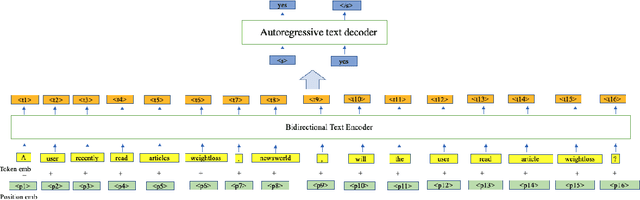

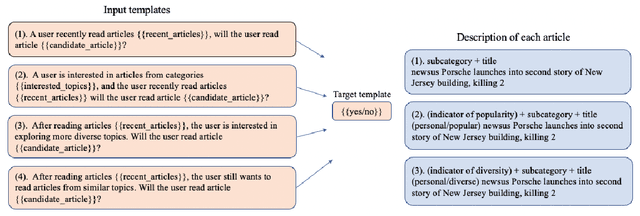
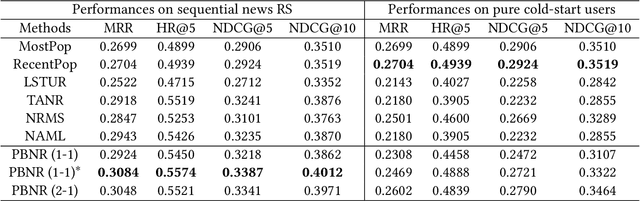
Online news platforms often use personalized news recommendation methods to help users discover articles that align with their interests. These methods typically predict a matching score between a user and a candidate article to reflect the user's preference for the article. Some previous works have used language model techniques, such as the attention mechanism, to capture users' interests based on their past behaviors, and to understand the content of articles. However, these existing model architectures require adjustments if additional information is taken into account. Pre-trained large language models, which can better capture word relationships and comprehend contexts, have seen a significant development in recent years, and these pre-trained models have the advantages of transfer learning and reducing the training time for downstream tasks. Meanwhile, prompt learning is a newly developed technique that leverages pre-trained language models by building task-specific guidance for output generations. To leverage textual information in news articles, this paper introduces the pre-trained large language model and prompt-learning to the community of news recommendation. The proposed model "prompt-based news recommendation" (PBNR) treats the personalized news recommendation as a text-to-text language task and designs personalized prompts to adapt to the pre-trained language model -- text-to-text transfer transformer (T5). Experimental studies using the Microsoft News dataset show that PBNR is capable of making accurate recommendations by taking into account various lengths of past behaviors of different users. PBNR can also easily adapt to new information without changing the model architecture and the training objective. Additionally, PBNR can make recommendations based on users' specific requirements, allowing human-computer interaction in the news recommendation field.