 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhysics-Informed Multi-Agent Reinforcement Learning for Distributed Multi-Robot Problems
Dec 30, 2023



The networked nature of multi-robot systems presents challenges in the context of multi-agent reinforcement learning. Centralized control policies do not scale with increasing numbers of robots, whereas independent control policies do not exploit the information provided by other robots, exhibiting poor performance in cooperative-competitive tasks. In this work we propose a physics-informed reinforcement learning approach able to learn distributed multi-robot control policies that are both scalable and make use of all the available information to each robot. Our approach has three key characteristics. First, it imposes a port-Hamiltonian structure on the policy representation, respecting energy conservation properties of physical robot systems and the networked nature of robot team interactions. Second, it uses self-attention to ensure a sparse policy representation able to handle time-varying information at each robot from the interaction graph. Third, we present a soft actor-critic reinforcement learning algorithm parameterized by our self-attention port-Hamiltonian control policy, which accounts for the correlation among robots during training while overcoming the need of value function factorization. Extensive simulations in different multi-robot scenarios demonstrate the success of the proposed approach, surpassing previous multi-robot reinforcement learning solutions in scalability, while achieving similar or superior performance (with averaged cumulative reward up to x2 greater than the state-of-the-art with robot teams x6 larger than the number of robots at training time).
Learning to Identify Graphs from Node Trajectories in Multi-Robot Networks
Jul 10, 2023



The graph identification problem consists of discovering the interactions among nodes in a network given their state/feature trajectories. This problem is challenging because the behavior of a node is coupled to all the other nodes by the unknown interaction model. Besides, high-dimensional and nonlinear state trajectories make difficult to identify if two nodes are connected. Current solutions rely on prior knowledge of the graph topology and the dynamic behavior of the nodes, and hence, have poor generalization to other network configurations. To address these issues, we propose a novel learning-based approach that combines (i) a strongly convex program that efficiently uncovers graph topologies with global convergence guarantees and (ii) a self-attention encoder that learns to embed the original state trajectories into a feature space and predicts appropriate regularizers for the optimization program. In contrast to other works, our approach can identify the graph topology of unseen networks with new configurations in terms of number of nodes, connectivity or state trajectories. We demonstrate the effectiveness of our approach in identifying graphs in multi-robot formation and flocking tasks.
Multi-robot Implicit Control of Massive Herds
Sep 20, 2022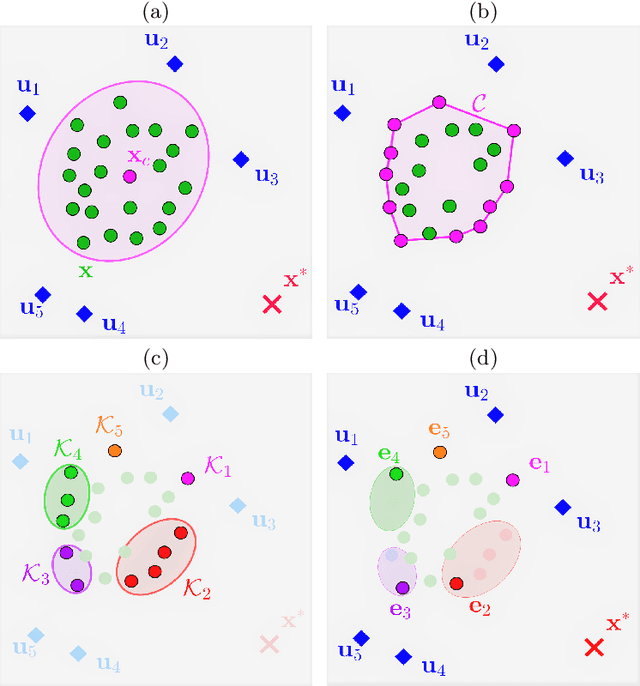
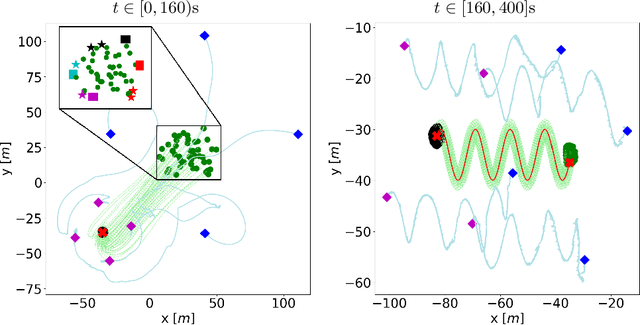
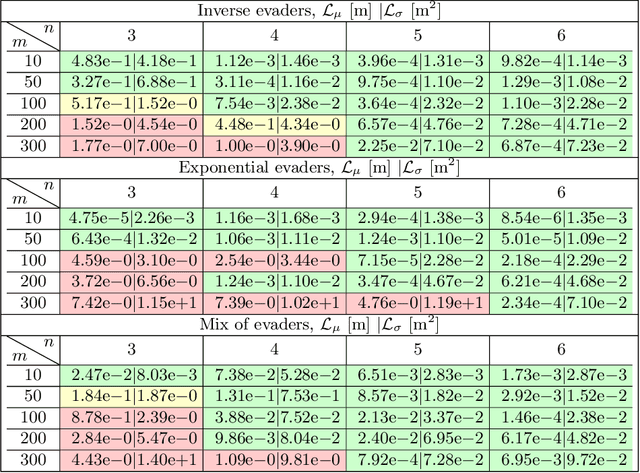
This paper solves the problem of herding countless evaders by means of a few robots. The objective is to steer all the evaders towards a desired tracking reference while avoiding escapes. The problem is very challenging due to the highly complex repulsive evaders' dynamics and the underdetermined states to control. We propose a solution that is based on Implicit Control and a novel dynamic assignment strategy to select the evaders to be directly controlled. The former is a general technique that explicitly computes control inputs even in highly complex input-nonaffine dynamics. The latter is built upon a convex-hull dynamic clustering inspired by the Voronoi tessellation problem. The combination of both allows to choose the best evaders to directly control, while the others are indirectly controlled by exploiting the repulsive interactions among them. Simulations show that massive herds can be herd throughout complex patterns by means of a few herders.
LEMURS: Learning Distributed Multi-Robot Interactions
Sep 20, 2022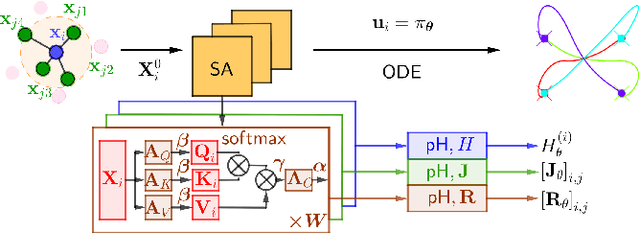
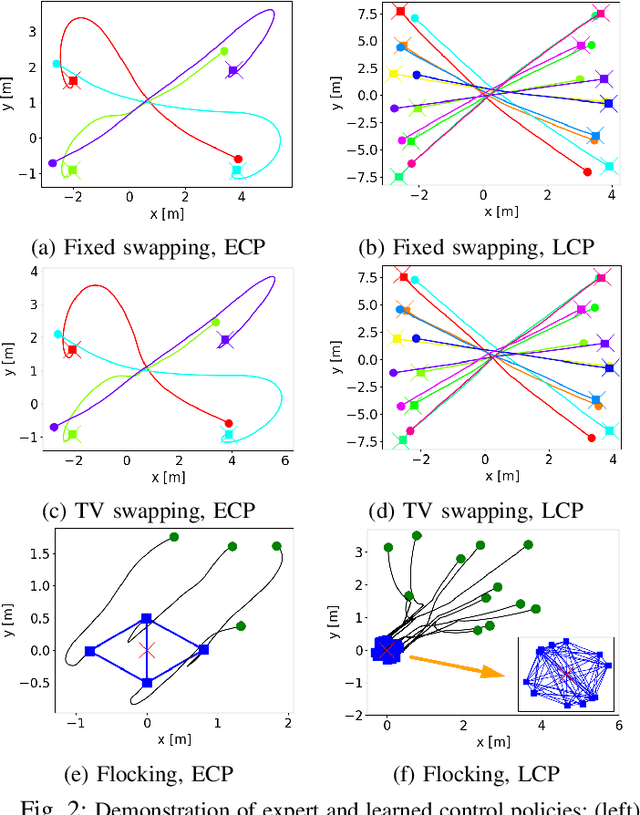
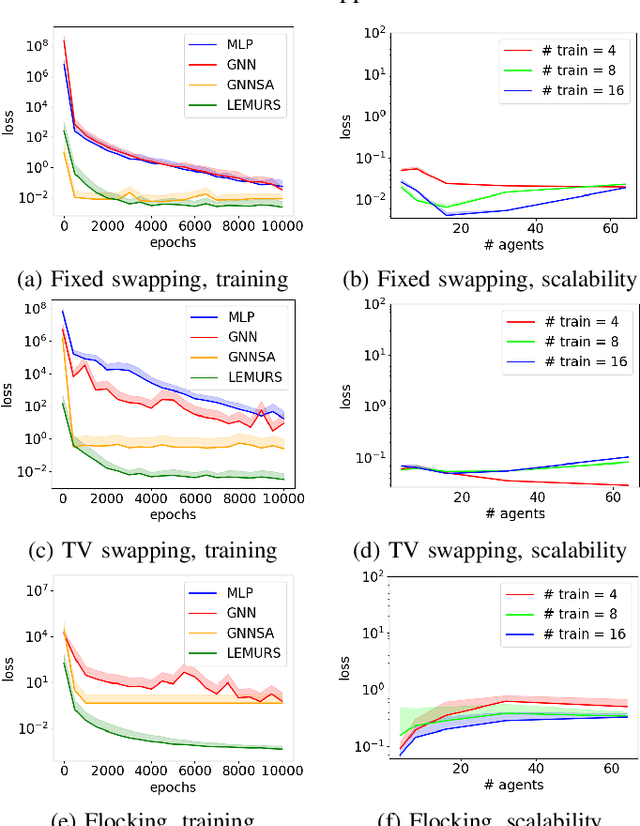
This paper presents LEMURS, an algorithm for learning scalable multi-robot control policies from cooperative task demonstrations. We propose a port-Hamiltonian description of the multi-robot system to exploit universal physical constraints in interconnected systems and achieve closed-loop stability. We represent a multi-robot control policy using an architecture that combines self-attention mechanisms and neural ordinary differential equations. The former handles time-varying communication in the robot team, while the latter respects the continuous-time robot dynamics. Our representation is distributed by construction, enabling the learned control policies to be deployed in robot teams of different sizes. We demonstrate that LEMURS can learn interactions and cooperative behaviors from demonstrations of multi-agent navigation and flocking tasks.