 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLEMURS: Learning Distributed Multi-Robot Interactions
Paper and Code
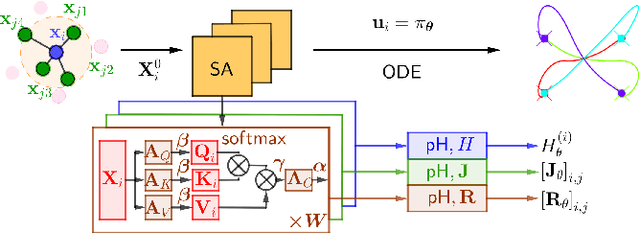
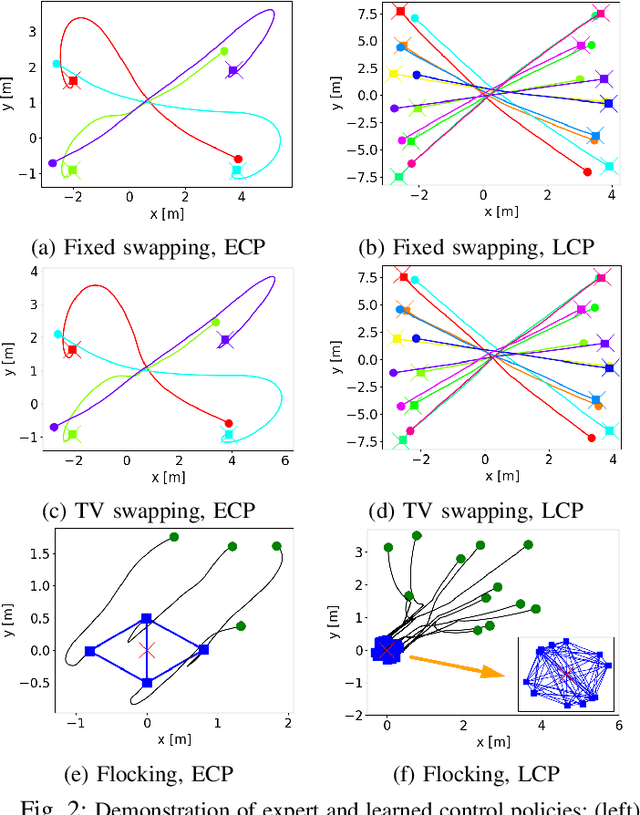
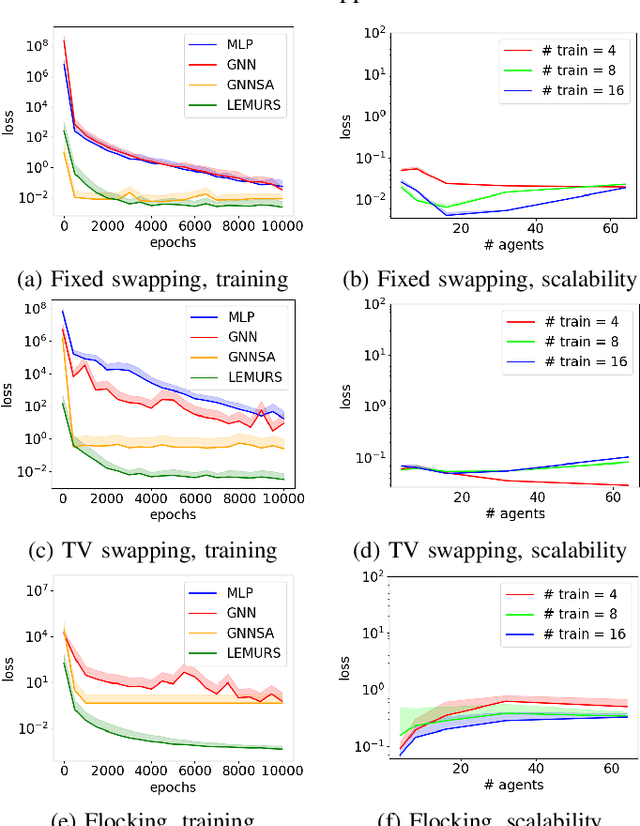
This paper presents LEMURS, an algorithm for learning scalable multi-robot control policies from cooperative task demonstrations. We propose a port-Hamiltonian description of the multi-robot system to exploit universal physical constraints in interconnected systems and achieve closed-loop stability. We represent a multi-robot control policy using an architecture that combines self-attention mechanisms and neural ordinary differential equations. The former handles time-varying communication in the robot team, while the latter respects the continuous-time robot dynamics. Our representation is distributed by construction, enabling the learned control policies to be deployed in robot teams of different sizes. We demonstrate that LEMURS can learn interactions and cooperative behaviors from demonstrations of multi-agent navigation and flocking tasks.