 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Hypothesis Visual-Inertial Flow
Mar 08, 2018
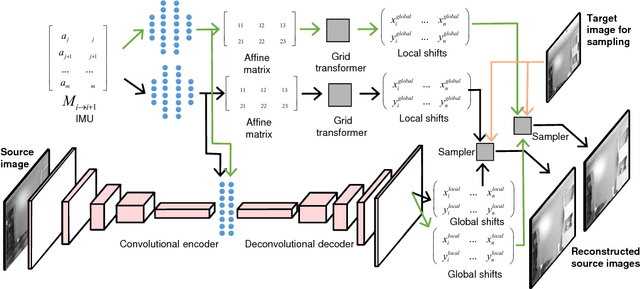

Estimating the correspondences between pixels in sequences of images is a critical first step for a myriad of tasks including vision-aided navigation (e.g., visual odometry (VO), visual-inertial odometry (VIO), and visual simultaneous localization and mapping (VSLAM)) and anomaly detection. We introduce a new unsupervised deep neural network architecture called the Visual Inertial Flow (VIFlow) network and demonstrate image correspondence and optical flow estimation by an unsupervised multi-hypothesis deep neural network receiving grayscale imagery and extra-visual inertial measurements. VIFlow learns to combine heterogeneous sensor streams and sample from an unknown, un-parametrized noise distribution to generate several (4 or 8 in this work) probable hypotheses on the pixel-level correspondence mappings between a source image and a target image . We quantitatively benchmark VIFlow against several leading vision-only dense correspondence and flow methods and show a substantial decrease in runtime and increase in efficiency compared to all methods with similar performance to state-of-the-art (SOA) dense correspondence matching approaches. We also present qualitative results showing how VIFlow can be used for detecting anomalous independent motion.
Vision-Aided Absolute Trajectory Estimation Using an Unsupervised Deep Network with Online Error Correction
Mar 08, 2018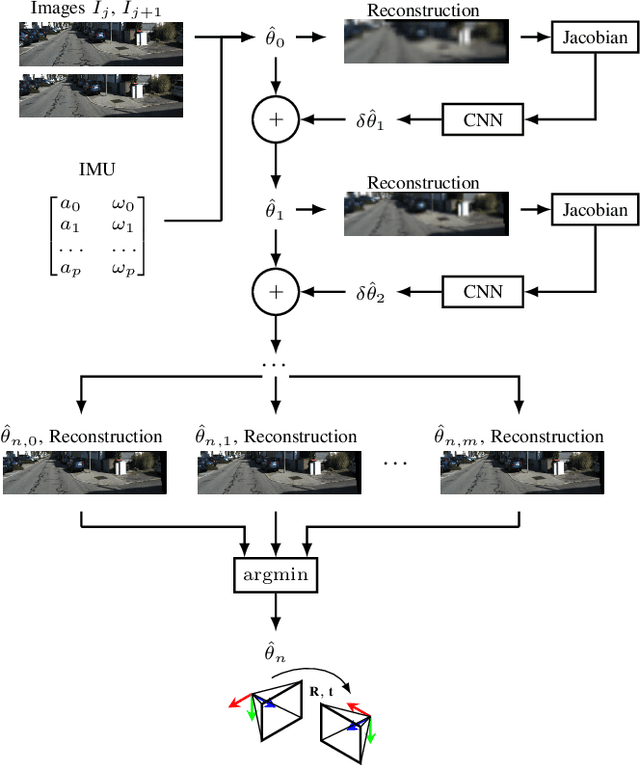
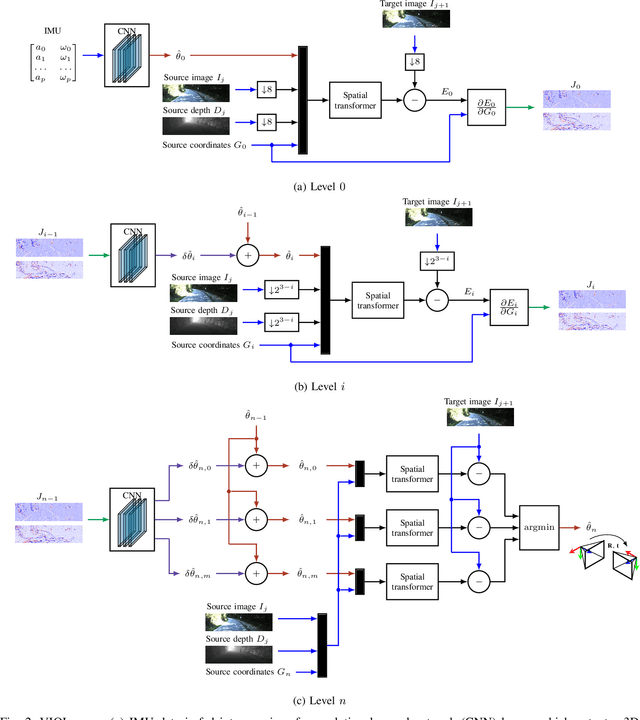
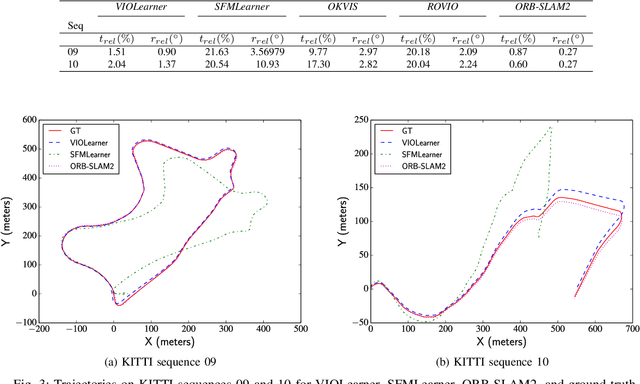
We present an unsupervised deep neural network approach to the fusion of RGB-D imagery with inertial measurements for absolute trajectory estimation. Our network, dubbed the Visual-Inertial-Odometry Learner (VIOLearner), learns to perform visual-inertial odometry (VIO) without inertial measurement unit (IMU) intrinsic parameters (corresponding to gyroscope and accelerometer bias or white noise) or the extrinsic calibration between an IMU and camera. The network learns to integrate IMU measurements and generate hypothesis trajectories which are then corrected online according to the Jacobians of scaled image projection errors with respect to a spatial grid of pixel coordinates. We evaluate our network against state-of-the-art (SOA) visual-inertial odometry, visual odometry, and visual simultaneous localization and mapping (VSLAM) approaches on the KITTI Odometry dataset and demonstrate competitive odometry performance.