 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIs human face processing a feature- or pattern-based task? Evidence using a unified computational method driven by eye movements
Sep 04, 2017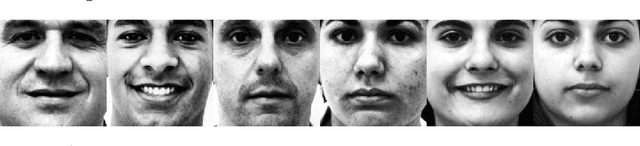
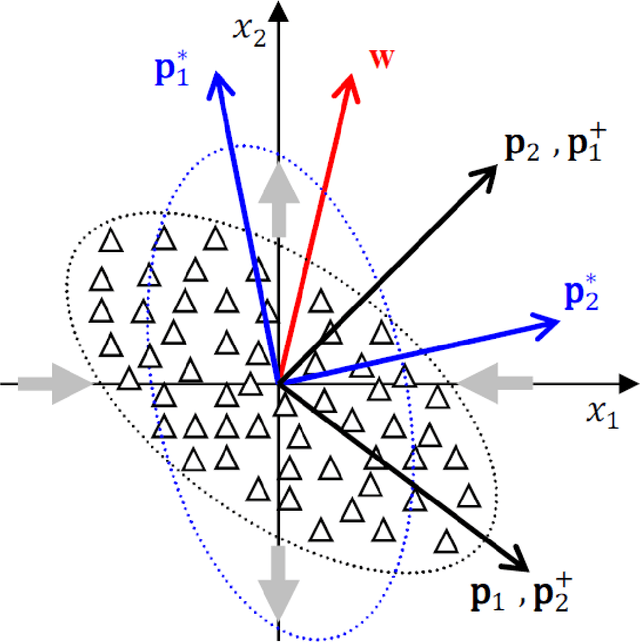

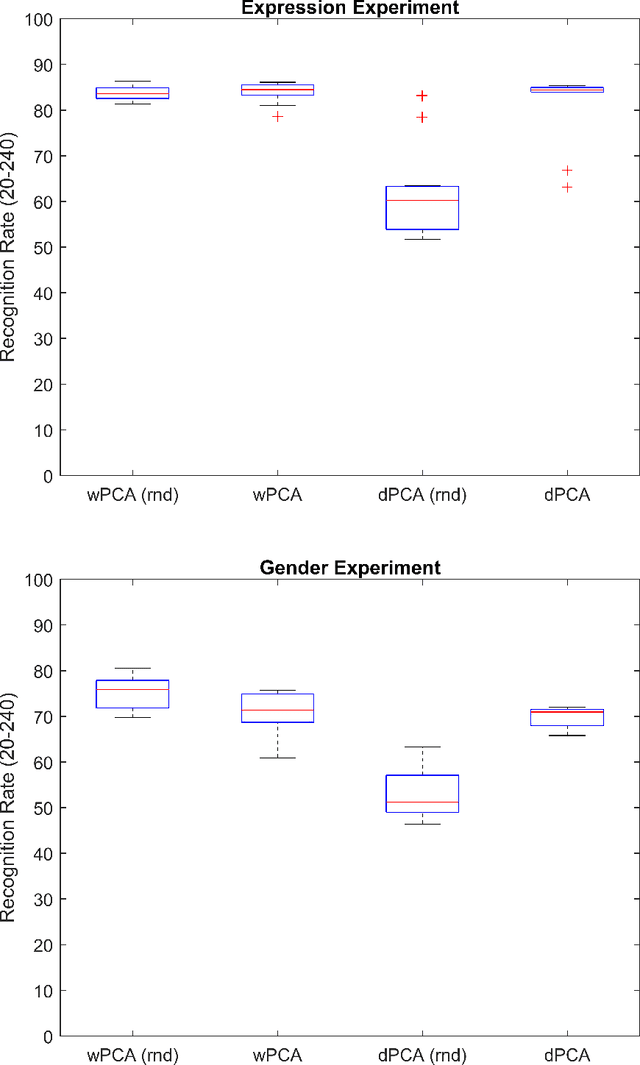
Research on human face processing using eye movements has provided evidence that we recognize face images successfully focusing our visual attention on a few inner facial regions, mainly on the eyes, nose and mouth. To understand how we accomplish this process of coding high-dimensional faces so efficiently, this paper proposes and implements a multivariate extraction method that combines face images variance with human spatial attention maps modeled as feature- and pattern-based information sources. It is based on a unified multidimensional representation of the well-known face-space concept. The spatial attention maps are summary statistics of the eye-tracking fixations of a number of participants and trials to frontal and well-framed face images during separate gender and facial expression recognition tasks. Our experimental results carried out on publicly available face databases have indicated that we might emulate the human extraction system as a pattern-based computational method rather than a feature-based one to properly explain the proficiency of the human system in recognizing visual face information.
Expressing Relational and Temporal Knowledge in Visual Probabilistic Networks
Mar 13, 2013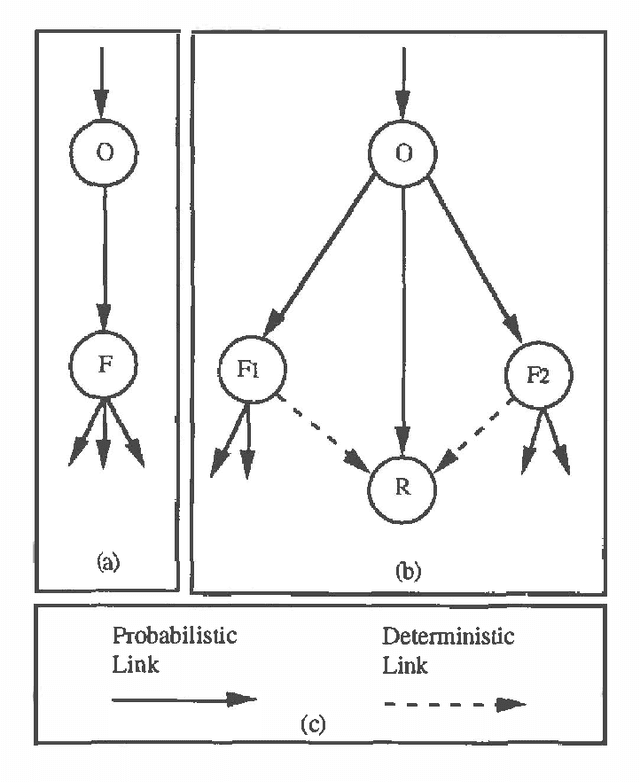
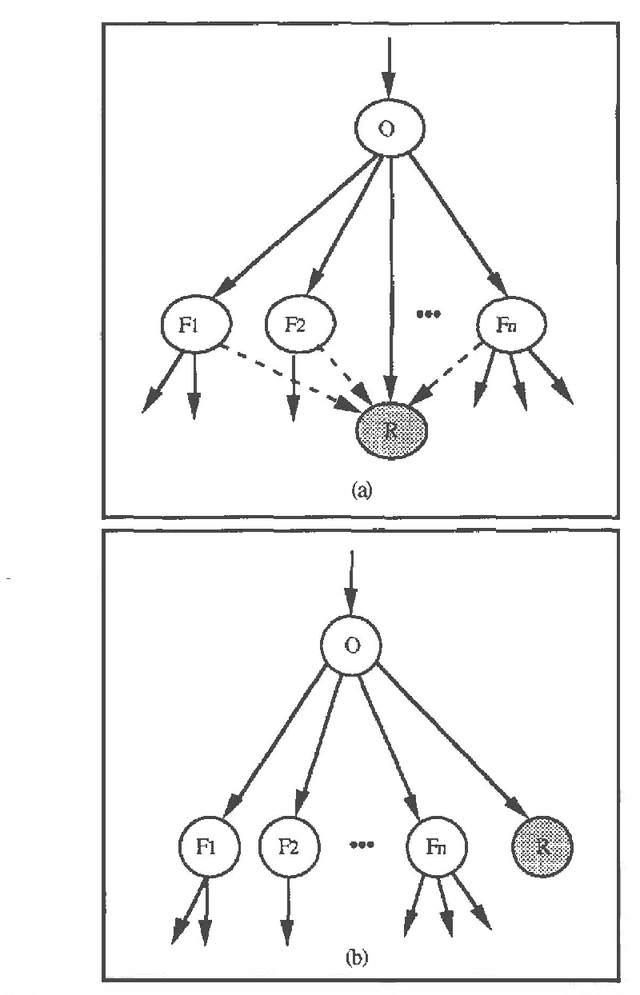
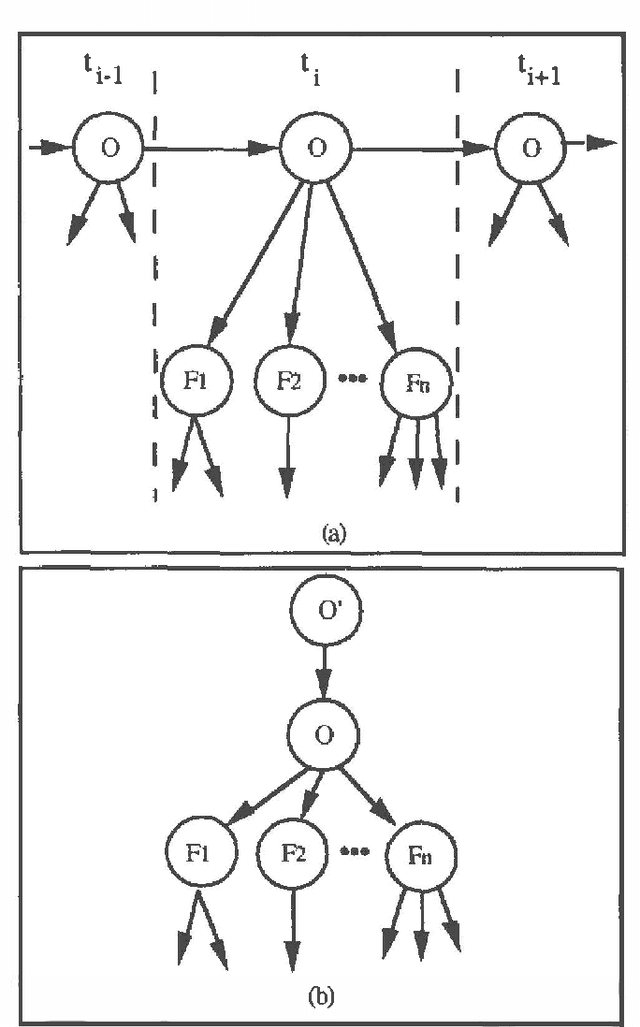
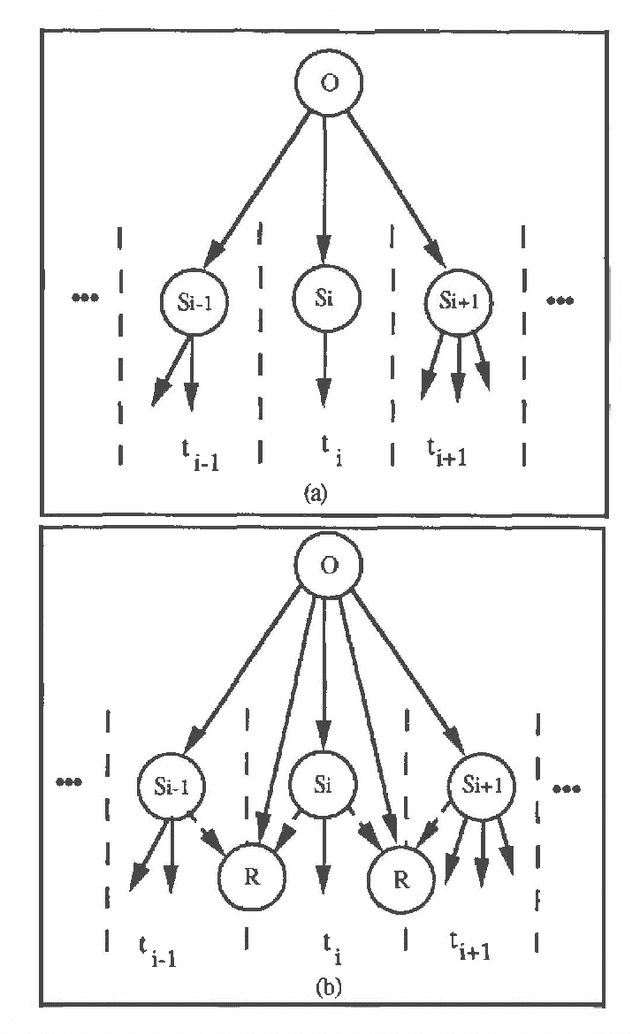
Bayesian networks have been used extensively in diagnostic tasks such as medicine, where they represent the dependency relations between a set of symptoms and a set of diseases. A criticism of this type of knowledge representation is that it is restricted to this kind of task, and that it cannot cope with the knowledge required in other artificial intelligence applications. For example, in computer vision, we require the ability to model complex knowledge, including temporal and relational factors. In this paper we extend Bayesian networks to model relational and temporal knowledge for high-level vision. These extended networks have a simple structure which permits us to propagate probability efficiently. We have applied them to the domain of endoscopy, illustrating how the general modelling principles can be used in specific cases.