 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnveiling Themes in Judicial Proceedings: A Cross-Country Study Using Topic Modeling on Legal Documents from India and the UK
May 27, 2024
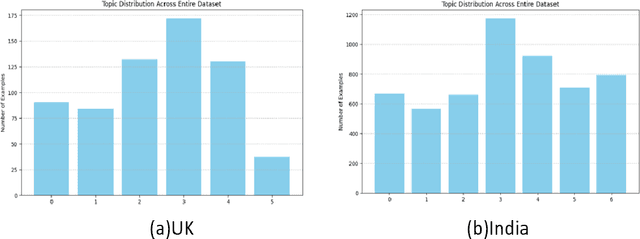
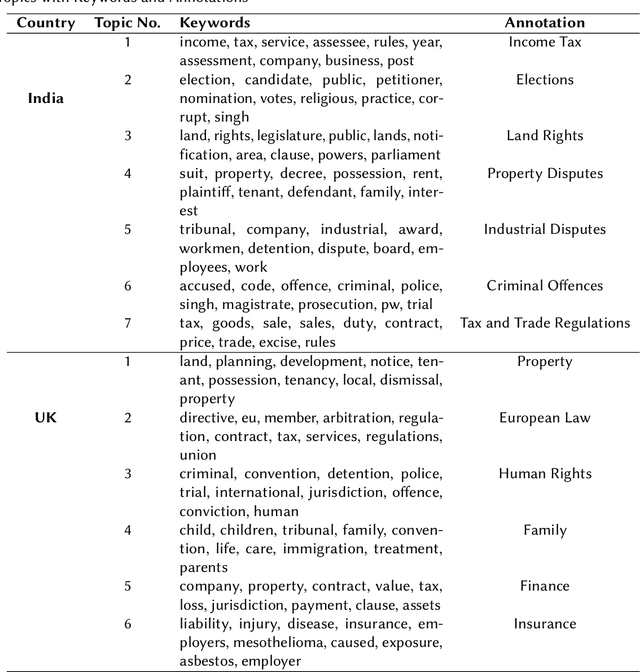
Legal documents are indispensable in every country for legal practices and serve as the primary source of information regarding previous cases and employed statutes. In today's world, with an increasing number of judicial cases, it is crucial to systematically categorize past cases into subgroups, which can then be utilized for upcoming cases and practices. Our primary focus in this endeavor was to annotate cases using topic modeling algorithms such as Latent Dirichlet Allocation, Non-Negative Matrix Factorization, and Bertopic for a collection of lengthy legal documents from India and the UK. This step is crucial for distinguishing the generated labels between the two countries, highlighting the differences in the types of cases that arise in each jurisdiction. Furthermore, an analysis of the timeline of cases from India was conducted to discern the evolution of dominant topics over the years.