 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpecializing Inter-Agent Communication in Heterogeneous Multi-Agent Reinforcement Learning using Agent Class Information
Dec 14, 2020

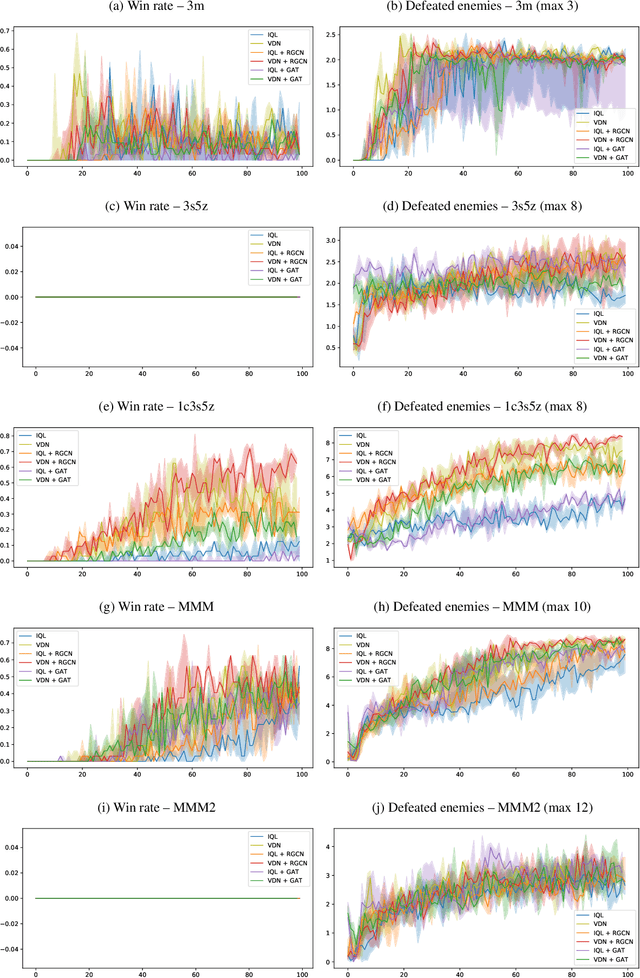

Inspired by recent advances in agent communication with graph neural networks, this work proposes the representation of multi-agent communication capabilities as a directed labeled heterogeneous agent graph, in which node labels denote agent classes and edge labels, the communication type between two classes of agents. We also introduce a neural network architecture that specializes communication in fully cooperative heterogeneous multi-agent tasks by learning individual transformations to the exchanged messages between each pair of agent classes. By also employing encoding and action selection modules with parameter sharing for environments with heterogeneous agents, we demonstrate comparable or superior performance in environments where a larger number of agent classes operates.
Towards Heterogeneous Multi-Agent Reinforcement Learning with Graph Neural Networks
Oct 20, 2020


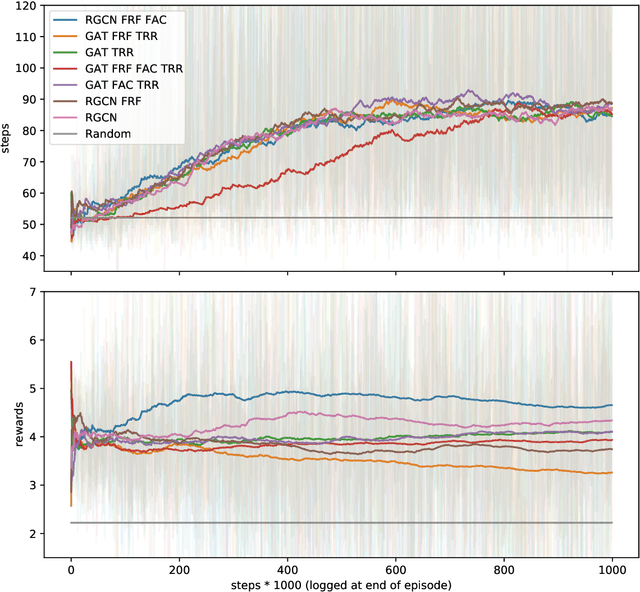
This work proposes a neural network architecture that learns policies for multiple agent classes in a heterogeneous multi-agent reinforcement setting. The proposed network uses directed labeled graph representations for states, encodes feature vectors of different sizes for different entity classes, uses relational graph convolution layers to model different communication channels between entity types and learns distinct policies for different agent classes, sharing parameters wherever possible. Results have shown that specializing the communication channels between entity classes is a promising step to achieve higher performance in environments composed of heterogeneous entities.
CAPTION: Correction by Analyses, POS-Tagging and Interpretation of Objects using only Nouns
Oct 02, 2020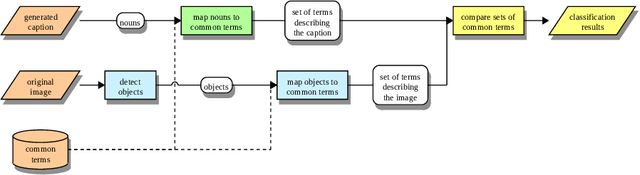
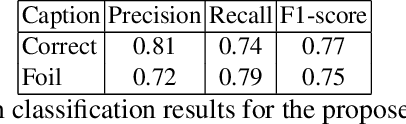

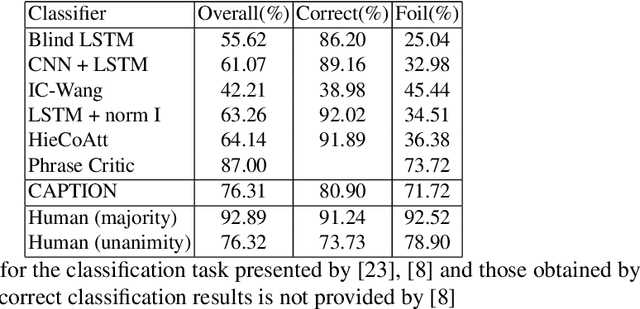
Recently, Deep Learning (DL) methods have shown an excellent performance in image captioning and visual question answering. However, despite their performance, DL methods do not learn the semantics of the words that are being used to describe a scene, making it difficult to spot incorrect words used in captions or to interchange words that have similar meanings. This work proposes a combination of DL methods for object detection and natural language processing to validate image's captions. We test our method in the FOIL-COCO data set, since it provides correct and incorrect captions for various images using only objects represented in the MS-COCO image data set. Results show that our method has a good overall performance, in some cases similar to the human performance.
Detecting soccer balls with reduced neural networks: a comparison of multiple architectures under constrained hardware scenarios
Sep 28, 2020
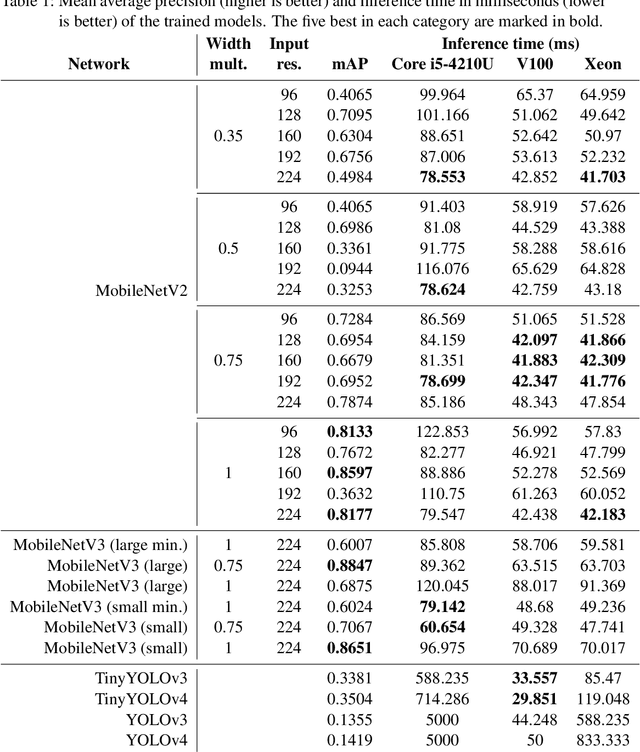
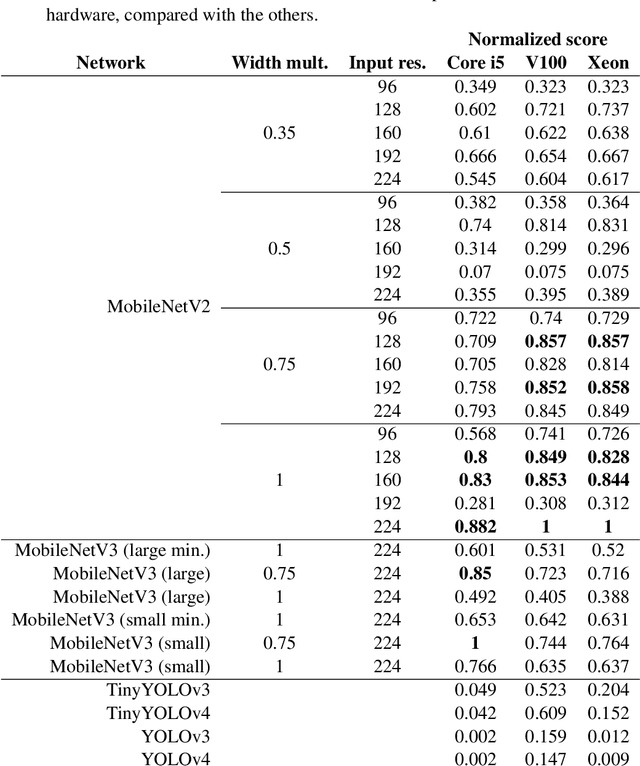
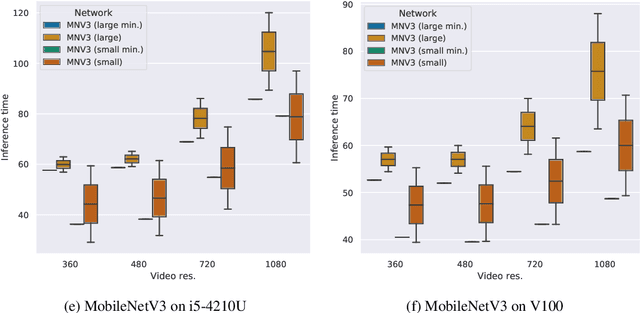
Object detection techniques that achieve state-of-the-art detection accuracy employ convolutional neural networks, implemented to have optimal performance in graphics processing units. Some hardware systems, such as mobile robots, operate under constrained hardware situations, but still benefit from object detection capabilities. Multiple network models have been proposed, achieving comparable accuracy with reduced architectures and leaner operations. Motivated by the need to create an object detection system for a soccer team of mobile robots, this work provides a comparative study of recent proposals of neural networks targeted towards constrained hardware environments, in the specific task of soccer ball detection. We train multiple open implementations of MobileNetV2 and MobileNetV3 models with different underlying architectures, as well as YOLOv3, TinyYOLOv3, YOLOv4 and TinyYOLOv4 in an annotated image data set captured using a mobile robot. We then report their mean average precision on a test data set and their inference times in videos of different resolutions, under constrained and unconstrained hardware configurations. Results show that MobileNetV3 models have a good trade-off between mAP and inference time in constrained scenarios only, while MobileNetV2 with high width multipliers are appropriate for server-side inference. YOLO models in their official implementations are not suitable for inference in CPUs.