 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetecting soccer balls with reduced neural networks: a comparison of multiple architectures under constrained hardware scenarios
Paper and Code

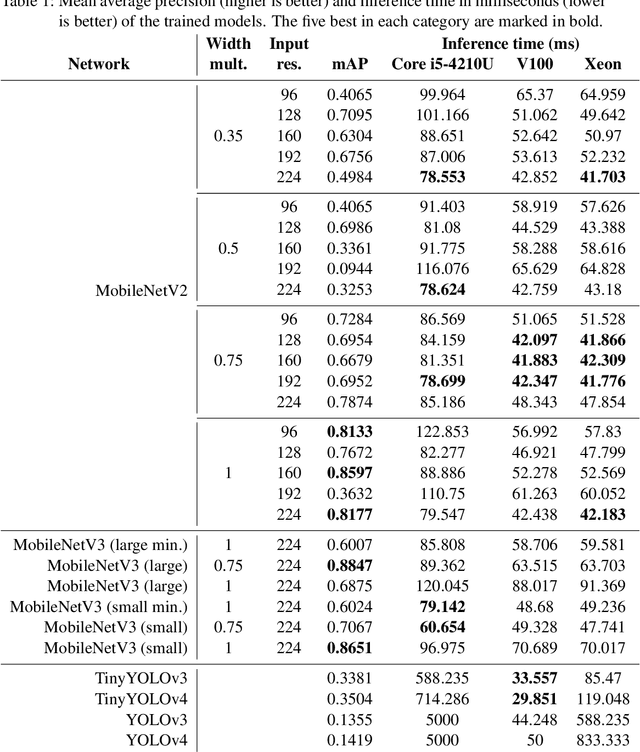
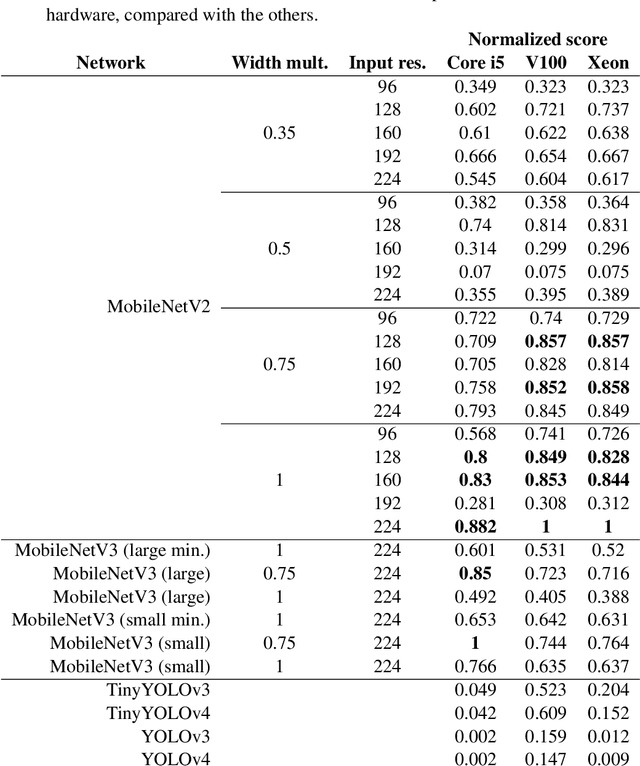
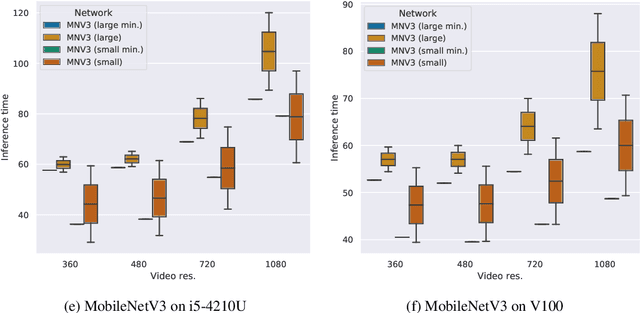
Object detection techniques that achieve state-of-the-art detection accuracy employ convolutional neural networks, implemented to have optimal performance in graphics processing units. Some hardware systems, such as mobile robots, operate under constrained hardware situations, but still benefit from object detection capabilities. Multiple network models have been proposed, achieving comparable accuracy with reduced architectures and leaner operations. Motivated by the need to create an object detection system for a soccer team of mobile robots, this work provides a comparative study of recent proposals of neural networks targeted towards constrained hardware environments, in the specific task of soccer ball detection. We train multiple open implementations of MobileNetV2 and MobileNetV3 models with different underlying architectures, as well as YOLOv3, TinyYOLOv3, YOLOv4 and TinyYOLOv4 in an annotated image data set captured using a mobile robot. We then report their mean average precision on a test data set and their inference times in videos of different resolutions, under constrained and unconstrained hardware configurations. Results show that MobileNetV3 models have a good trade-off between mAP and inference time in constrained scenarios only, while MobileNetV2 with high width multipliers are appropriate for server-side inference. YOLO models in their official implementations are not suitable for inference in CPUs.