 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCAPTION: Correction by Analyses, POS-Tagging and Interpretation of Objects using only Nouns
Oct 02, 2020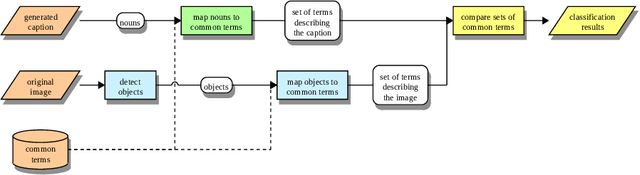
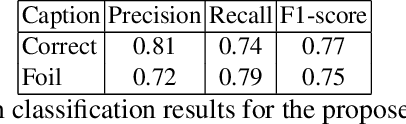

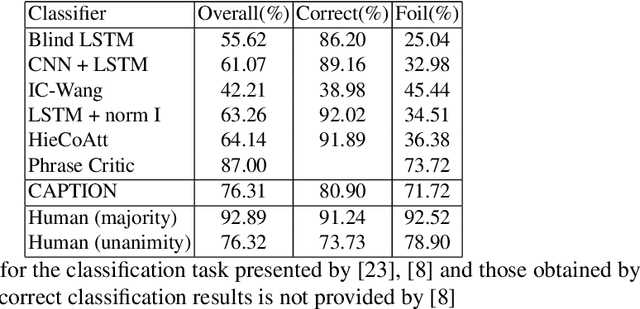
Recently, Deep Learning (DL) methods have shown an excellent performance in image captioning and visual question answering. However, despite their performance, DL methods do not learn the semantics of the words that are being used to describe a scene, making it difficult to spot incorrect words used in captions or to interchange words that have similar meanings. This work proposes a combination of DL methods for object detection and natural language processing to validate image's captions. We test our method in the FOIL-COCO data set, since it provides correct and incorrect captions for various images using only objects represented in the MS-COCO image data set. Results show that our method has a good overall performance, in some cases similar to the human performance.