 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnergy-efficient Dense DNN Acceleration with Signed Bit-slice Architecture
Mar 15, 2022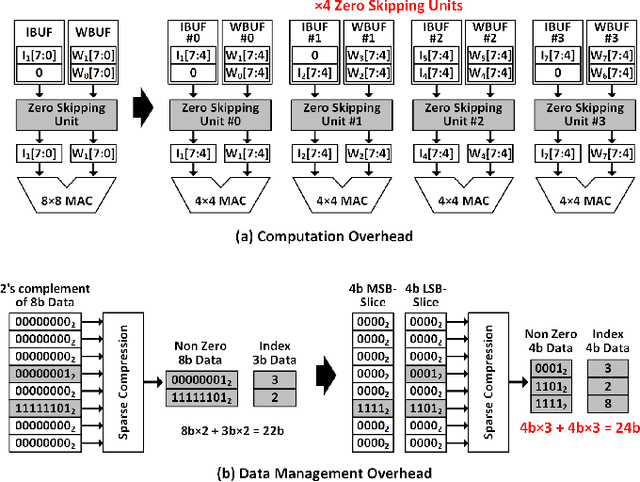
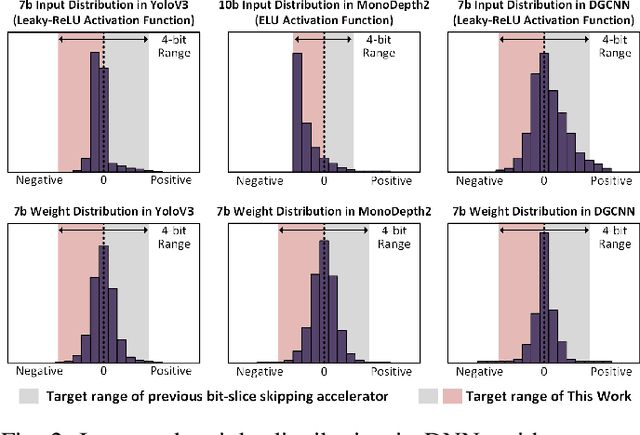

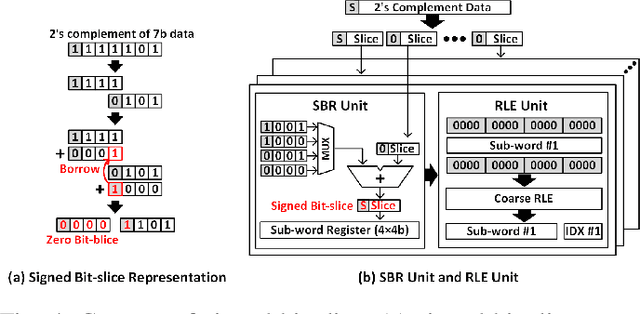
As the number of deep neural networks (DNNs) to be executed on a mobile system-on-chip (SoC) increases, the mobile SoC suffers from the real-time DNN acceleration within its limited hardware resources and power budget. Although the previous mobile neural processing units (NPUs) take advantage of low-bit computing and exploitation of the sparsity, it is incapable of accelerating high-precision and dense DNNs. This paper proposes energy-efficient signed bit-slice architecture which accelerates both high-precision and dense DNNs by exploiting a large number of zero values of signed bit-slices. Proposed signed bit-slice representation (SBR) changes signed $1111_{2}$ bit-slice to $0000_{2}$ by borrowing a $1$ value from its lower order of bit-slice. As a result, it generates a large number of zero bit-slices even in dense DNNs. Moreover, it balances the positive and negative values of 2's complement data, allowing bit-slice based output speculation which pre-computes high order of bit-slices and skips the remaining dense low order of bit-slices. The signed bit-slice architecture compresses and skips the zero input signed bit-slices, and the zero skipping unit also supports the output skipping by masking the speculated inputs as zero. Additionally, the heterogeneous network-on-chip (NoC) benefits the exploitation of data reusability and reduction of transmission bandwidth. The paper introduces a specialized instruction set architecture (ISA) and a hierarchical instruction decoder for the control of the signed bit-slice architecture. Finally, the signed bit-slice architecture outperforms the previous bit-slice accelerator, Bit-fusion, over $\times3.65$ higher area-efficiency, $\times3.88$ higher energy-efficiency, and $\times5.35$ higher throughput.