 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeK-medoids Clustering of Data Sequences with Composite Distributions
Jul 31, 2018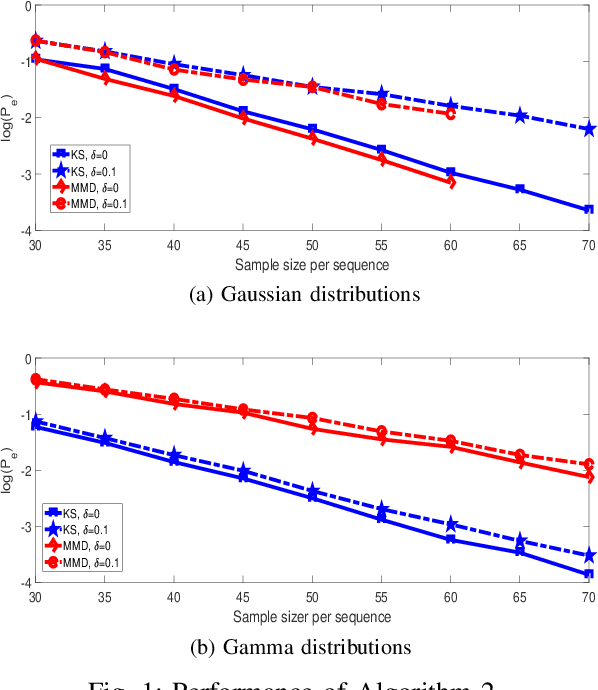
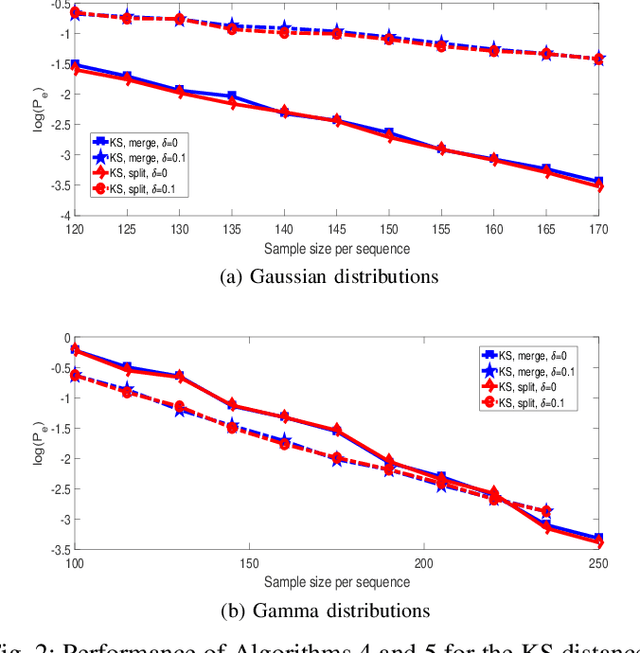
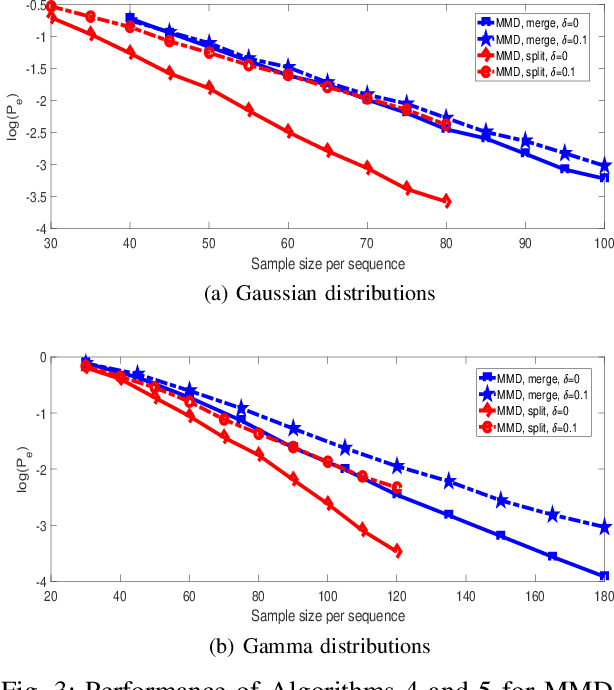
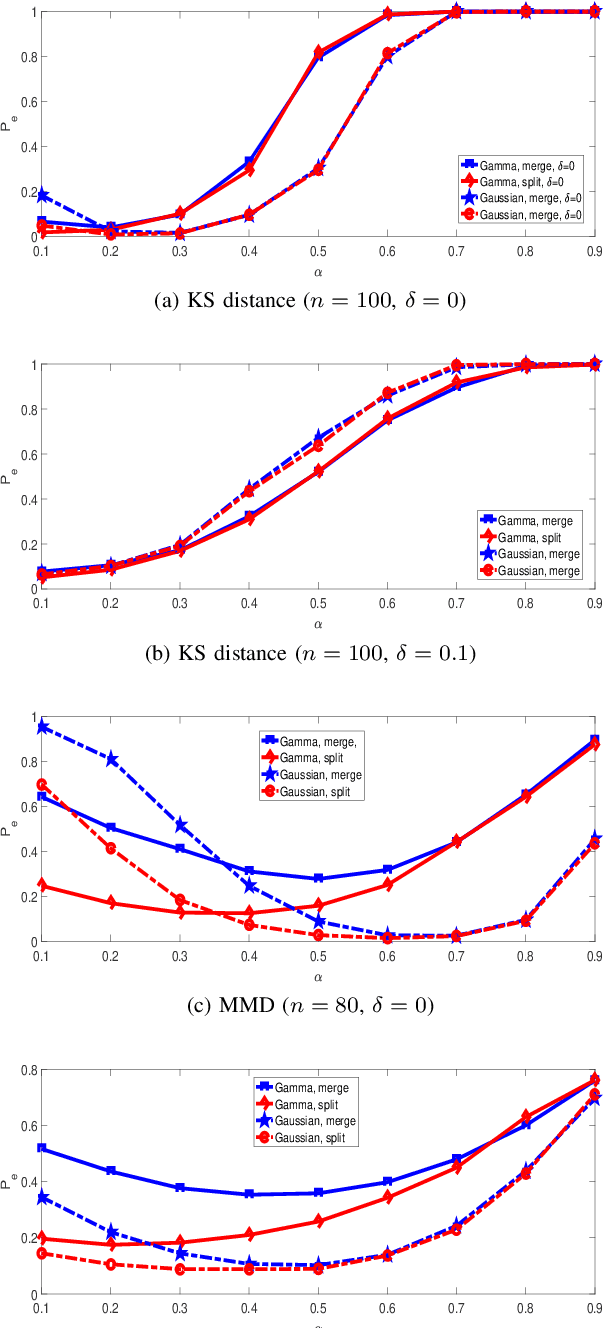
This paper studies clustering of data sequences using the k-medoids algorithm. All the data sequences are assumed to be generated from \emph{unknown} continuous distributions, which form clusters with each cluster containing a composite set of closely located distributions (based on a certain distance metric between distributions). The maximum intra-cluster distance is assumed to be smaller than the minimum inter-cluster distance, and both values are assumed to be known. The goal is to group the data sequences together if their underlying generative distributions (which are unknown) belong to one cluster. Distribution distance metrics based k-medoids algorithms are proposed for known and unknown number of distribution clusters. Upper bounds on the error probability and convergence results in the large sample regime are also provided. It is shown that the error probability decays exponentially fast as the number of samples in each data sequence goes to infinity. The error exponent has a simple form regardless of the distance metric applied when certain conditions are satisfied. In particular, the error exponent is characterized when either the Kolmogrov-Smirnov distance or the maximum mean discrepancy are used as the distance metric. Simulation results are provided to validate the analysis.