 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLinking Tweets with Monolingual and Cross-Lingual News using Transformed Word Embeddings
Oct 25, 2017


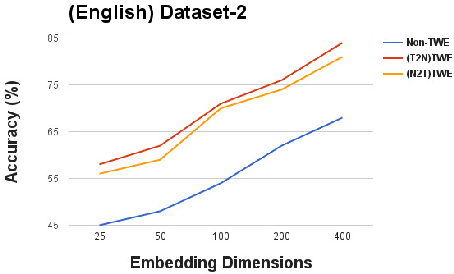
Social media platforms have grown into an important medium to spread information about an event published by the traditional media, such as news articles. Grouping such diverse sources of information that discuss the same topic in varied perspectives provide new insights. But the gap in word usage between informal social media content such as tweets and diligently written content (e.g. news articles) make such assembling difficult. In this paper, we propose a transformation framework to bridge the word usage gap between tweets and online news articles across languages by leveraging their word embeddings. Using our framework, word embeddings extracted from tweets and news articles are aligned closer to each other across languages, thus facilitating the identification of similarity between news articles and tweets. Experimental results show a notable improvement over baselines for monolingual tweets and news articles comparison, while new findings are reported for cross-lingual comparison.